UVM中的各种端口就可以实现这样的功能, 在monitor和 scoreboard之间专门建立一个通道, 让信息只能在这个通道内流动, scoreboard也只能从这个通道中接收信息,
这样几乎就可以保证scoreboard中的信息只能从monitor中来, 而不能从别的地方来; 同时赋予这个通道阻塞或者非阻塞等特性。
这就省去了用户浪费大量时间编写通信相关的代码.
TLM 的定义
TLM是Transaction Level Modeling( 事务级建模) 的缩写, 它起源于SystemC的一种通信标准。 所谓transaction level是相对
DUT中各个模块之间信号线级别的通信来说的。 简单来说, 一个transaction就是把具有某一特定功能的一组信息封装在一起而成为
的一个类。 如my_transaction就是把一个MAC帧里的各个字段封装在了一起。
put

通信的发起者A把一个transaction发送给B。 在这个过程中, A称为“发起者”, 而B称为“目标”。
A具有的端口( 用方框表示) 称为PORT, 而B的端口( 用圆圈表示) 称为EXPORT。 这个过程中, 数据流是从A流向B的
get

A向B索取一个transaction。 在这个过程中, A依然是“发起者”, B依然是“目标”, A上的端口依然是
PORT, 而B上的端口依然是EXPORT。 这个过程中, 数据流是从B流向A的。 到这里, 读者应该意识到, PORT和EXPORT体现的
是控制流而不是数据流。 因为在put操作中, 数据流是从PORT流向EXPORT的, 而在get操作中, 数据是从EXPORT流向PORT
的。 但是无论是get还是put操作, 其发起者拥有的都是PORT端口, 而不是EXPORT。 作为一个EXPORT来说, 只能被动地接收
PORT的命令
transport

transport操作相当于一次put操作加一次get操作, 这两次操作的“发起者”都是A, 目标都是 B。
A上的端口依然是PORT, 而B上的端口依然是EXPORT。 在这个过程中, 数据流先从A流向B, 再从B流向A。
在现实世界中, 相当于是A向B提交了一个请求(request) , 而B返回给A一个应答(response)。
所以这种transport操作也常常被称做request-response操作
put、 get和transport操作都有阻塞和非阻塞之分
UVM中的PORT与EXPORT
常用的PORT 有
|
|
三个put系列端口对应的是TLM中的put操作,
三个get系列端口对应的是get操作,
三个transport系列端口对应的是则是transport 操作( request-response操作)
三个peek系列端口, 它们与get系列端口类似, 用于主动获取数据, 它与get 操作的区别将在4.3.4节中看到
三个get_peek系列端口, 它集合了get操作和peek操作两者的功能
其中T 表示PORT 中的数据流类型, (REQ, RSP) 表示transport操作中发起请求时传输的数据类型和返回的数据类型
带blocking 的是阻塞
带nonblocking 的是非阻塞
即不带blocking 也不带nonblocking 的是即可以阻塞也可以非阻塞
常用的EXPORT 有
|
|
PORT和EXPORT体现的是一种控制流, 在这种控制流中, PORT具有高优先级, 而EXPORT具有低优先级。 只有高优先级的端口才能向低优先级的端口发起三种操作
UVM 中各种端口的互连
PORT与EXPORT的连接
UVM中使用connect函数来建立连接关系, 如A要和B通信( A是发起者) , 那么可以这么写: A.port.connect( B.export) , 但
是不能写成B.export.connect( A.port) 。 因为在通信的过程中, A是发起者, B是被动承担者。 这种通信时的主次顺序也适用于连
接时, 只有发起者才能调用connect函数, 而被动承担者则作为connect的参数, 示例:
|
|
其中A_port在实例化的时候比较奇怪, 第一个参数是名字, 而第二个参数则是一个uvm_component类型的父结点变量。 事实
上, 一个uvm_blocking_put_port的new函数的原型如下:
|
|
new函数中的min_size和max_size指的是必须连接到这个PORT的下级端口数量的最小值和最大值,
也即这一个PORT应该调用的connect函数的最小值和最大值。 如果采用默认值, 即min_size=max_size=1, 则只能连接一个EXPORT。
B 代码为:
|
|
在env中建立两者之间的连接:
|
|
运行上述代码会报错
|
|
原因是连接不完整, 需要IMP
UVM中的IMP
除了TLM中定义的PORT与EXPORT外, UVM中加入了第三种端口: IMP。 IMP才是UVM中的精髓, 承担了UVM中TLM的绝
大部分实现代码。 UVM中的IMP如下所示:
|
|
按照控制流的优先级排序, UVM中三种端口顺序为: PORT、 EXPORT、 IMP。 IMP的优先级最低, 一个PORT可以连接到一个IMP, 并发起三种操作, 反之则不行。
示例:
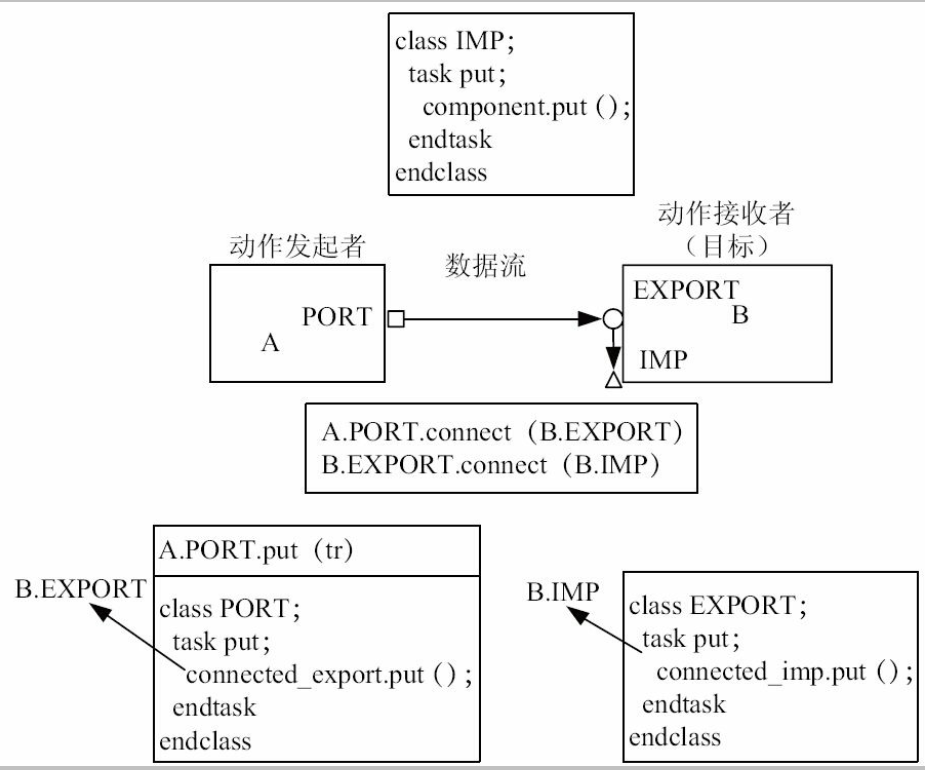
A.A_port.put( transaction) 这个任务会调用B.B_export的put, B.B_export的put( transaction)
又会调用B.B_imp的 put( transaction) , 而B_imp.put最终又会调用B的相关任务, 如B.put( transaction)
A 代码:
|
|
B 代码:
|
|
在B的代码中, 关键是要实现一个put函数/任务。 如果不实现, 将会给出如下的错误提示:
|
|
运行上述代码, 可以见到B正确地收到了A发出的transaction。 在上述连接关系中, IMP是作为连接的终点。
在UVM中, 只有IMP才能作为连接关系的终点。 如果是PORT或者EXPORT作为终点, 则会报错
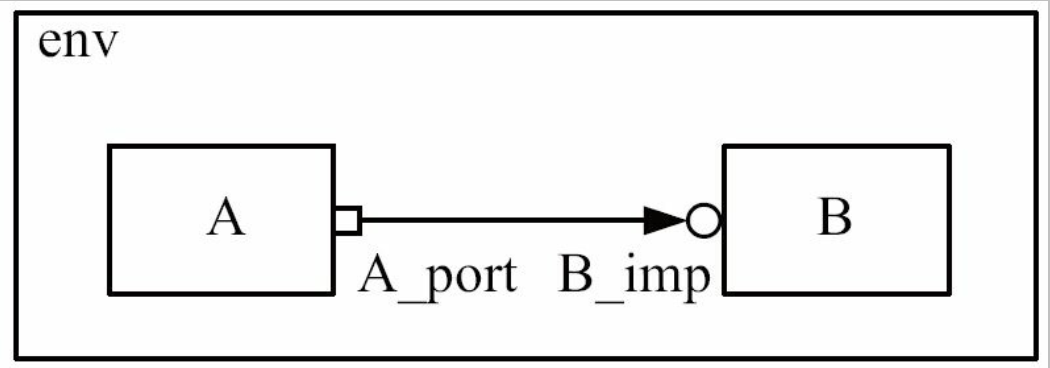
PORT 与 IMP 的连接
A 代码:
|
|
B 代码:
|
|
由于A中采用了blocking_put类型的PORT, 所以在B中IMP相应的类型是uvm_blocking_put_imp,
env 代码:
|
|
当A_port的类型是blocking_put , B_imp的类型是blocking_put 时
那么就要在B中定义一个名字为put的函数/任务
当A_port的类型是nonblocking_put , B_imp的类型是nonblocking_put 时
那么就要在B中定义一个名字为try_put的函数和一个名为can_put的函数
当A_port的类型是put, B_imp的类型是put时
那么就要在B中定义3个接口, 一个是put任务/函数, 一个是try_put函数, 一个是can_put函数。
当A_port的类型是blocking_get, B_imp的类型是blocking_get时
那么就要在B中定义一个名字为get的任务/函数
当A_port的类型是nonblocking_get, B_imp的类型是nonblocking_get时
那么就要在B中定义一个名字为try_get的函数和一个名为can_get的函数
当A_port的类型是get, B_imp的类型是get时
那么就要在B中定义3个接口, 一个是get任务/函数, 一个是try_get函数, 一个是can_get函数
当A_port的类型是blocking_peek, B_imp的类型是blocking_peek时
那么就要在B中定义一个名字为peek的任务/函数
当A_port的类型是nonblocking_peek, B_imp的类型是nonblocking_peek时
那么就要在B中定义一个名字为try_peek的函数和一个名为can_peek的函数
当A_port的类型是peek, B_imp的类型是peek时
那么就要在B中定义3个接口, 一个是peek任务/函数, 一个是try_peek函数,一个是can_peek函数
当A_port的类型是blocking_get_peek, B_imp的类型是blocking_get_peek时
那么就要在B中定义一个名字为get的任务/函数, 一个名字为peek的任务/函数
当A_port的类型是nonblocking_get_peek, B_imp的类型是nonblocking_get_peek时
那么就要在B中定义一个名字为try_get的函数, 一个名为can_get的函数, 一个名字为try_peek的函数和一个名为can_peek的函数
当A_port的类型是get_peek, B_imp的类型是get_peek时
那么就要在B中定义6个接口, 一个是get任务/函数, 一个是try_get函数, 一个是can_get函数, 一个是peek任务/函数,
一个是try_peek函数, 一个是can_peek函数
当A_port的类型是blocking_transport, B_imp的类型是blocking_transport时
那么就要在B中定义一个名字为transport的任务/函数。
当A_port的类型是nonblocking_transport, B_imp的类型是nonblocking_transport时
那么就要在B中定义一个名字为nb_transport 的函数
当A_port的类型是transport, B_imp的类型是transport时
那么就要在B中定义两个接口, 一个是transport任务/函数, 一个是 nb_transport函数
规律总结
在前述的这些规律中, 对于所有blocking系列的端口来说, 可以定义相应的任务或函数, 如对于blocking_put端口来说, 可以定
义名字为put的任务, 也可以定义名字为put的函数。 这是因为A会调用B中名字为put的接口, 而不管这个接口的类型。 由于A中的
put是个任务, 所以B中的put可以是任务, 也可以是函数。 但是对于nonblocking系列端口来说, 只能定义函数。
EXPORT 与 IMP 的连接
要实现A中的EXPORT与B中的IMP连接, A的代码为:
|
|
B 代码:
|
|
env 代码:
|
|
规律与 PORT 和 IMP 的连接一样
PORT 与 PORT 的连接
在UVM中, 支持带层次的连接关系
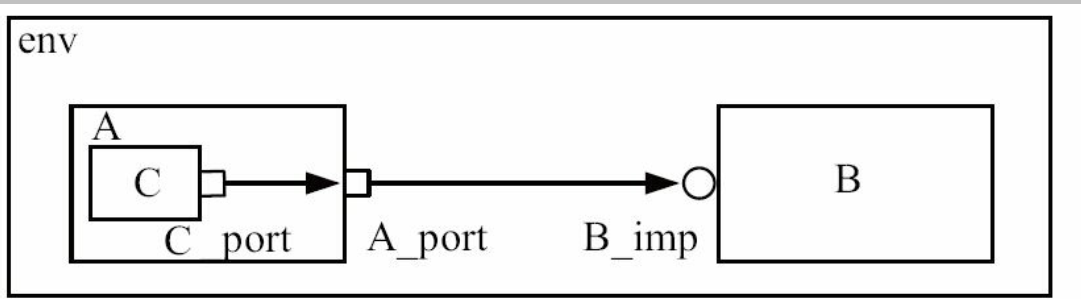
在上图中, A与C中是PORT, B中是IMP。 UVM支持C的PORT连接到A的PORT, 并最终连接到B的IMP。
C 的代码:
|
|
A 代码:
|
|
B 代码:
|
|
由于A中采用了blocking_put类型的PORT, 所以在B中IMP相应的类型是uvm_blocking_put_imp,
env 代码:
|
|
PORT与PORT之间的连接不只局限于两层, 可以有无限多层。
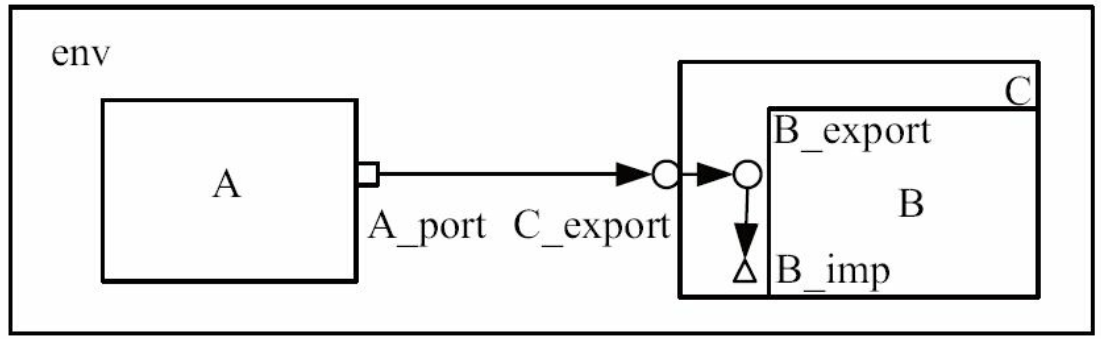
EXPORT 与 EXPORT 的连接
在下图中, A中是PORT, B与C中是EXPORT, B中还有一个IMP。 UVM支持C的EXPORT连接到B的EXPORT, 并最终连接到B的IMP
C 代码:
|
|
A 代码:
|
|
B 代码:
|
|
env 代码:
|
|
同样的, EXPORT与EXPORT之间的连接也不只局限于两层, 也可以有无限多层
blocking_get端口的使用
get系列端口与put系列端口在某些方面完全相反
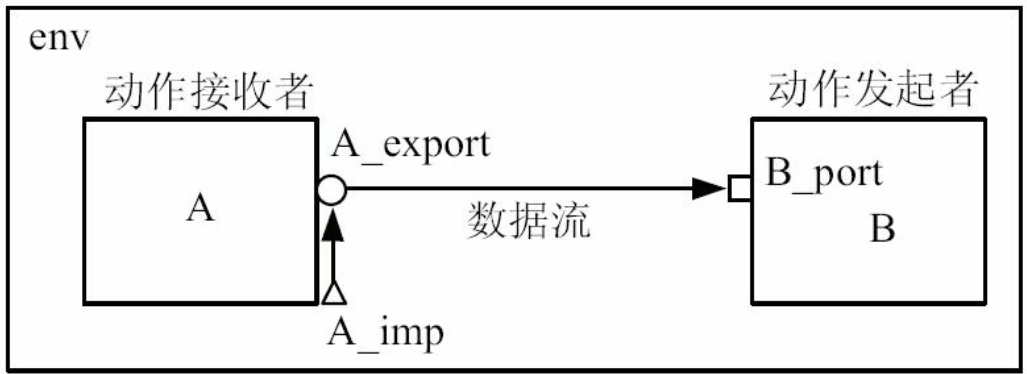
在这种连接关系中, 数据流依然是从A到B, 但是A由动作发起者变成了动作接收者, 而B由动作接收者变成了动作发起者。
B_port的类型为uvm_blocking_get_port, A_export的类型为uvm_blocking_get_export, A_imp的类型为uvm_blocking_get_imp。
与 uvm_blocking_put_imp所在的component要实现一个put的函数/任务类似, uvm_blocking_get_imp所在的component要实现一个名字为 get的函数/任务。
A的代码为:
|
|
B 代码:
|
|
env 代码:
|
|
blocking_transport端口的使用
transport系列端口与put和get系列端口都不一样。 在put和get系列端口中, 所有的通信都是单向的, 而在transport系列端口中,通信变成了双向的

A 代码:
|
|
B 代码:
|
|
env 代码:
|
|
在A中调用transport任务, 并把生成的transaction作为第一个参数。 B中的transaport任务接收到这个transaction, 根据这个
transaction做某些操作, 并把操作的结果作为transport的第二个参数发送出去。 A根据接收到的rsp来决定后面的行为。
nonblocking端口的使用
nonblocking端口的所有操作都是非阻塞的, 换言之, 必须用函数实现, 而不能用任务实现。 下面以nonblocking_put端口为例介绍nonblocking端口的使用
要实现下面连接关系
A 代码:
|
|
由于端口变为了非阻塞的, 所以在送出transaction之前需要调用can_put函数来确认是否能够执行put操作。 can_put最终会调用 B中的can_put
其实这里还可以不用can_put, 而直接使用try_put:
B 代码:
|
|
即使A 中不使用can_put, 在B中依然需要定义一个名字为can_put的函数, 这个函数里可以没有任何内容, 纯粹是一个空函数
env 代码:
|
|
UVM中的通信方式
UVM中的analysis端口
除了PORT 、 EXPORT 、 IMP 这几种端口外 ,UVM中还有两种特殊的端口:analysis_port和analysis_export。
这两者其实与put和get系列端口类似,都用于传递transaction。它们的区别是:
- 第一,默认情况下,一个analysis_port(analysis_export)可以连接多个IMP ,也就是说,analysis_port(analysis_export)与IMP 之间的通信是一对多的通信,
而put和get系列端口与相应IMP 的通信是一对一的通信(除非在实例化时指定可以连接的数量,参照 4.2.1节A_port的new函数原型代码清单4-4)。analysis_port(analysis_export)更像是一个广播
- 第二,put与get系列端口都有阻塞和非阻塞的区分。但是对于analysis_port和analysis_export来说,没有阻塞和非阻塞的概念。 因为它本身就是广播,不必等待与其相连的其他端口的响应,所以不存在阻塞和非阻塞
- 第三, 一个analysis_port可以和多个IMP 相连接进行通信,但是IMP 的类型必须是uvm_analysis_imp,否则会报错
- 第四, 对于put系列端口,有put、try_put、can_put等操作,对于get系列端口,有get、try_get和can_get等操作。
对于analysis_port和 analysis_export来说,只有一种操作:write。在analysis_imp所在的component,必须定义一个名字为write的函数。
要实现以下链接
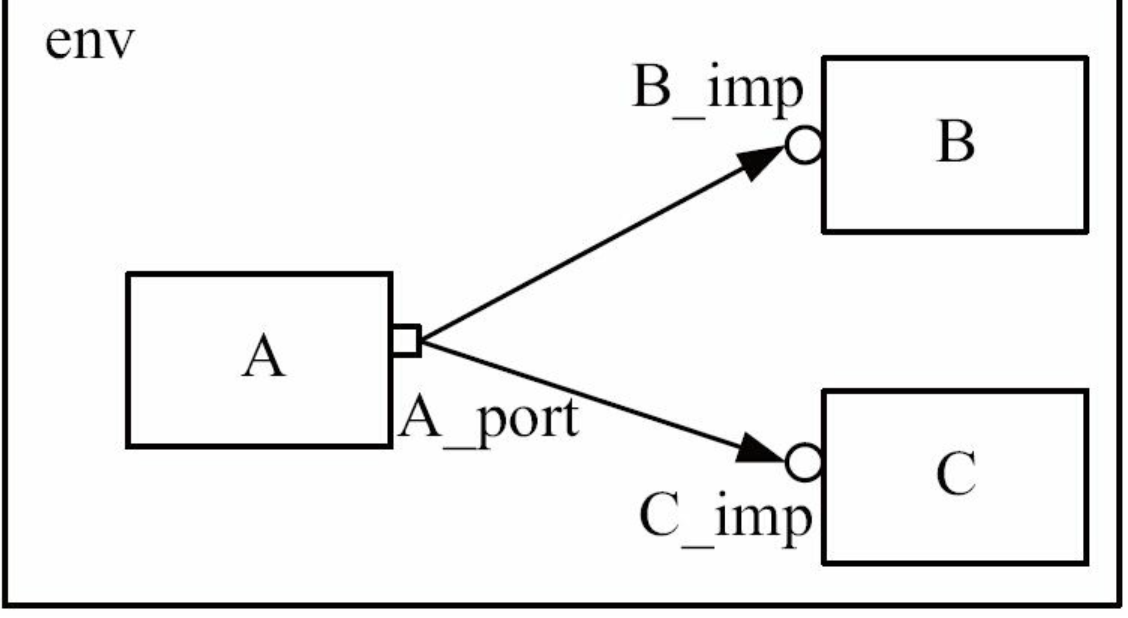
A 的代码为:
|
|
B 代码:
|
|
如前所述,B是B_imp所在的component,因此要在B中定义一个名字为write的函数。在B的main_phase中不需要做任何操作。
C 代码:
|
|
env 代码:
|
|
与put系列端口的PORT和EXPORT直接相连会出错的情况一样,analysis_port如果和一个analysis_export直接相连也会出错。只
有在analysis_export后面再连接一级uvm_analysis_imp,才不会出错
上面只是一个analysis_port与IMP相连的例子。analysis_export和IMP也可以这样相连接,只需将上面例子中的
uvm_analysis_port改为uvm_analysis_export就可以
一个component内有多个IMP
-
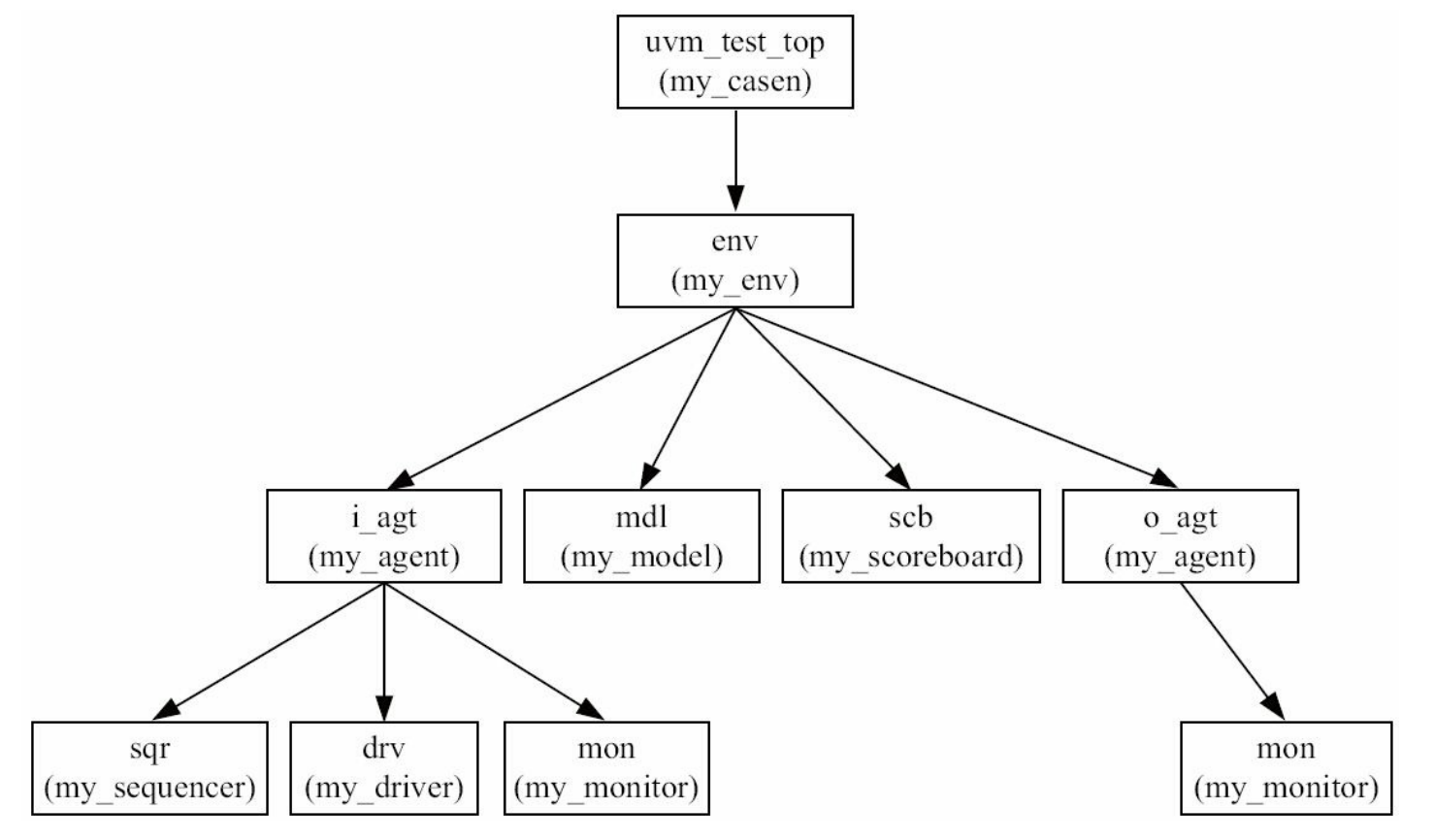
跨层次IMP 的使用
考虑上图中o_agt的monitor与scoreboard之间的通信,使用analysis_port实现。
monitor 代码:1 2 3 4 5 6 7 8 9 10class monitor extends uvm_monitor; uvm_analysis_port#(my_transaction) ap; task main_phase(uvm_phase phase); super.main_phase(phase); my_transaction tr; … ap.write(tr); … endtask endclassscoreboard 代码:
1 2 3 4 5 6class scoreboard extends uvm_scoreboard; uvm_analysis_imp#(my_transaction, scoreboard) scb_imp; task write(my_transaction tr); //do something on tr endtask endclass之后在env中可以使用connect连接。由于monitor与scoreboard在UVM树中并不是平等的兄妹关系,其中间还间隔了o_agt,所以这里有三种连接方式,
第一种是直接在env中跨层次引用monitor中的ap:1 2 3 4function void my_env::connect_phase(uvm_phase phase); o_agt.mon.ap.connect(scb.scb_imp); … endfunction第二种是在agent中声明一个ap并实例化它,在connect_phase将其与monitor的ap相连,并可以在env中把agent的ap直接连接到 scoreboard的imp:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17class my_agent extends uvm_agent ; uvm_analysis_port #(my_transaction) ap; … function void build_phase(uvm_phase phase); super.build_phase(phase); ap = new("ap", this); … endfunction function void my_agent::connect_phase(uvm_phase phase); mon.ap.connect(this.ap); … endfunction endclass function void my_env::connect_phase(uvm_phase phase); o_agt.ap.connect(scb.scb_imp); … endfunction第三种是在agent中声明一个ap,但是不实例化它,让其指向monitor中的ap。在env中可以直接连接agent的ap到scoreboard的 imp:
1 2 3 4 5 6 7 8 9 10 11 12class my_agent extends uvm_agent ; uvm_analysis_port #(my_transaction) ap; … function void my_agent::connect_phase(uvm_phase phase); ap = mon.ap; … endfunction endclass function void my_env::connect_phase(uvm_phase phase); o_agt.ap.connect(scb.scb_imp); … endfunction如上所述的三种方式中,第一种最简单,但是其层次关系并不好,第二种稍显麻烦,第三种既具有明显的层次关系,同时其
实现也较简单。
-
当一个component 中有多个IMP
如 scb 中即要接收来自 monitor 的数据, 又要接收来自 refrence 的数据, 就需要两个 IMP ,
但是write 函数只有一个, 怎么办呢?
UVM考虑到了这种情况,它定义了一个宏uvm_analysis_imp_decl来解决这个问题,其使用方式为:1 2 3 4 5 6 7 8 9 10 11 12文件:src/ch4/section4.3/4.3.3/my_scoreboard.sv `uvm_analysis_imp_decl(_monitor) `uvm_analysis_imp_decl(_model) class my_scoreboard extends uvm_scoreboard; my_transaction expect_queue[$]; uvm_analysis_imp_monitor#(my_transaction, my_scoreboard) monitor_imp; uvm_analysis_imp_model#(my_transaction, my_scoreboard) model_imp; … extern function void write_monitor(my_transaction tr); extern function void write_model(my_transaction tr); extern virtual task main_phase(uvm_phase phase); endclass上述代码通过宏uvm_analysis_imp_decl声明了两个后缀_monitor和_model。
UVM会根据这两个后缀定义两个新的IMP类: uvm_analysis_imp_monitor和uvm_analysis_imp_model,
并在my_scoreboard中分别实例化这两个类:monitor_imp和model_imp。当与 monitor_imp相连接的analysis_port执行write函数时,会自动调用write_monitor函数,而与model_imp相连接的analysis_port执行write 函数时,会自动调用write_model函数。所以,只要完成后缀的声明,并在write后面添加上相应的后缀就可以正常工作了1 2 3 4 5 6 7 8 9 10 11文件:src/ch4/section4.3/4.3.3/my_scoreboard.sv function void my_scoreboard::write_model(my_transaction tr); expect_queue.push_back(tr); endfunction function void my_scoreboard::write_monitor(my_transaction tr); my_transaction tmp_tran; bit result; if(expect_queue.size() > 0) begin … end endfunction
使用FIFO通信
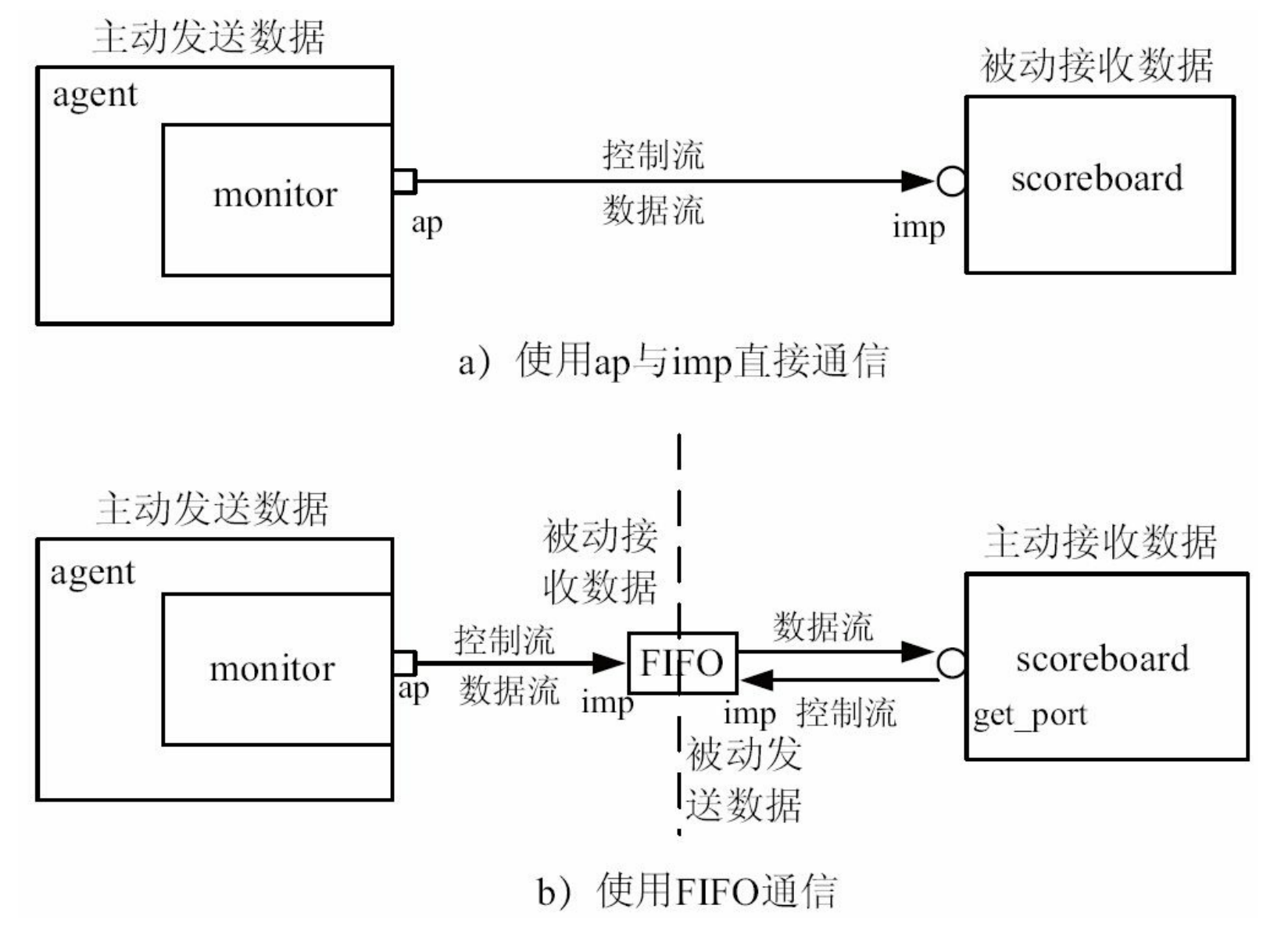
在agent和scoreboard之间添加一个uvm_analysis_fifo。FIFO的本质是一块缓存加两个IMP。在monitor与FIFO的
连接关系中,monitor中依然是analysis_port,FIFO中是uvm_analysis_imp,数据流和控制流的方向相同。在scoreboard与FIFO的连接关系中,scoreboard中使用blocking_get_port端口:
scoreboard 代码:
|
|
而FIFO中使用的是一个get端口的IMP。在这种连接关系中,控制流是从scoreboard到FIFO,而数据流是从FIFO到scoreboard
env 中代码 :
|
|
FIFO中有两个IMP,但是在上面的连接关系中,FIFO中却是EXPORT,这是为什么呢?实际上,FIFO中的 analysis_export和blocking_get_export虽然名字中有关键字export,
但是其类型却是IMP。UVM为了掩饰IMP的存在,在它们的命名中加入了export关键字。如analysis_export的原型如下:
|
|
analysis_export 是FIFO 的输入端, 即往FIFO 写数据
blocking_get_export 是FIFO 的输出端, 即从FIFO 读数据
使用FIFO连接之后,第一个好处是不必在scoreboard中再写一个名字为write的函数。scoreboard可以按照自己的节奏工作,而不必跟着monitor的节奏。
第二个好处是FIFO的存在隐藏了IMP,这对于初学者来说比较容易理解。第三个好处是可以轻易解决上 一节讲到的当reference model和monitor同时连接到scoreboard应如何处理的问题。
事实上,FIFO的存在自然而然地解决了它,这根本就不是一个问题了
FIFO上的端口及调试
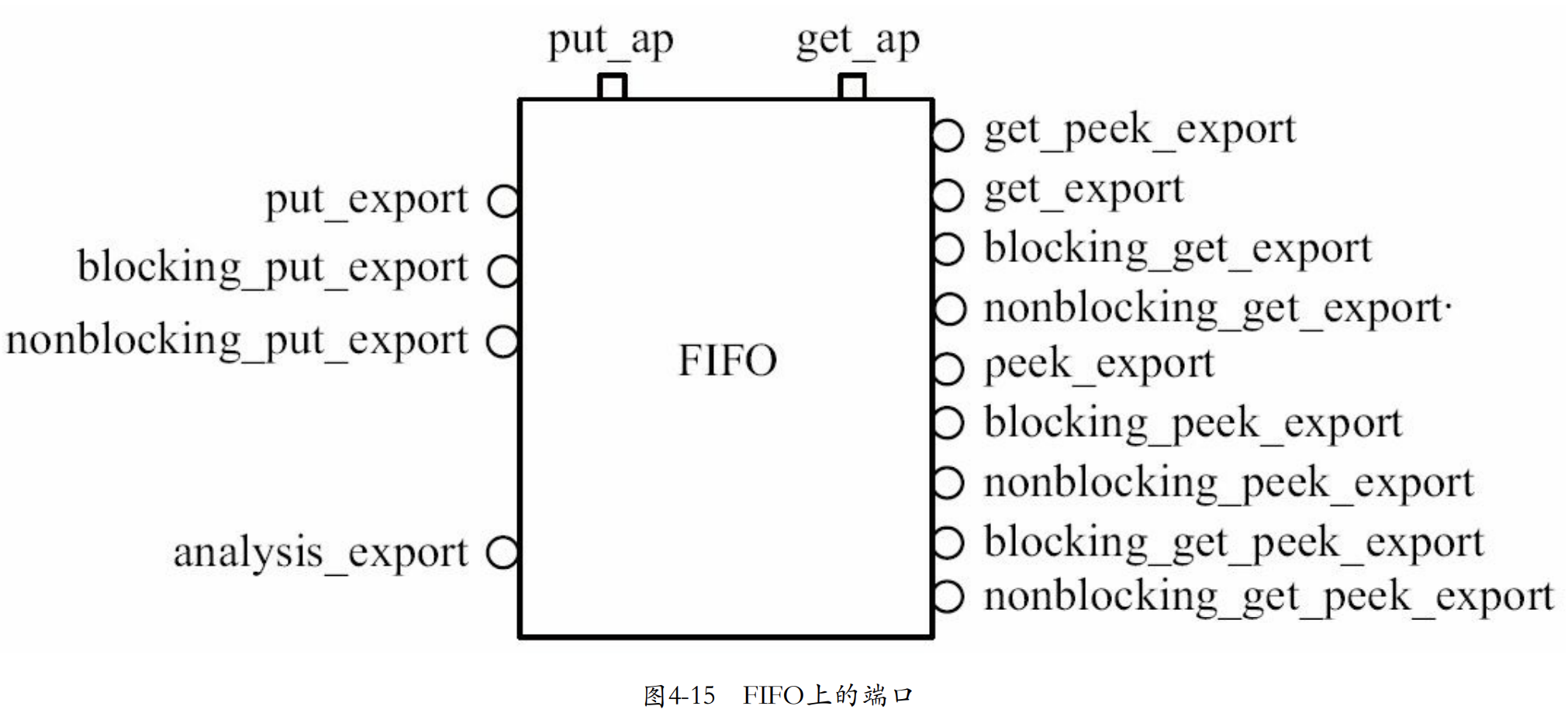
- put_ap
- get_ap
- put_export
- blocking_put_export
- nonblocking_put_export
- analysis_export
- get_peek_export
- get_export
- blocking_get_export
- nonblocking_get_export
- peek_export
- blocking_peek_export
- nonblocking_peek_export
- blocking_get_peek_export
- nonblocking_get_peek_export
上图中所有以圆圈表示的EXPORT虽然名字中有export,但是本质上都是IMP.
FIFO 中的peek 端口
peek端口与get相似,其数据流、控制流都相似,唯一的区别在于当get任务被调用时,FIFO内部缓存中会少一个transaction,
而peek被调用时,FIFO会把transaction复制一份发送出去,其内部缓存中的transaction数量并不会减少
analysis_port:put_ap和get_ap
当FIFO上的blocking_put_export或者put_export被连接到一个blocking_put_port或者put_port上时,FIFO内部被定义的put任务被调用,
这个put任务把传递过来的transaction放在FIFO内部的缓存里,同时,把这个transaction通过put_ap使用write函数发送出去。FIFO的put任务定义如下:
|
|
与put_ap相似,当FIFO的get任务被调用时,同样会有一个transaction从get_ap上发出
|
|
什么时候会触发FIFO中的这个get任务呢?在上一节中,一个blocking_get_port连接到了FIFO上,当它调用get任务获取
transaction时就会调用FIFO的get任务。除此之外,FIFO的get_export、get_peek_export和blocking_get_peek_export被相应的PORT或
者EXPORT连接时,也能会调用FIFO的get任务
FIFO 的类型
FIFO的类型有两种,一种是 uvm_tlm_analysis_fifo ,另外一种是 uvm_tlm_fifo 。这两者的唯一差别在于前者有一个
analysis_export端口,并且有一个write函数,而后者没有。除此之外,本节上面介绍的所有端口同时适用于这两者。
FIFO 的调试
-
used 函数
used函数用于查询FIFO缓存中有多少transaction。
-
is_empty函数
用于判断当前FIFO缓存是否为空。
-
is_full 函数
用于判断当前FIFO缓存是否已经满了。
-
size 函数
作为一个缓存来说,其能存储的transaction是有限的。那么这个最大值是在哪里定义的呢?
FIFO的new函数原型如下:1function new(string name, uvm_component parent = null, int size = 1);FIFO在本质上是一个component,所以其前两个参数是uvm_component的new函数中的两个参数。第三个参数是size,用于设定FIFO缓存的上限,在默认的情况下为1。
若要把缓存设置为无限大小,将传入的size参数设置为0即可。通过size函数可以返回这个上限值
-
flush 函数
1virtual function void flush();这个函数用于清空FIFO缓存中的所有数据,它一般用于复位等操作。
用FIFO还是用IMP
在用FIFO通信的方法中,完全隐藏了IMP这个UVM中特有、而TLM中根本就没有的东西。用户可以完全不关心IMP。
因此,对于用户来说,只需要知道analysis_port、blocking_get_port即可。这大大简化了初学者
的工作量。尤其是在scoreboard面临多个IMP,且需要为IMP声明一个后缀时,这种优势更加明显。
FIFO连接的方式增加了env中代码的复杂度,满满的看上去似乎都是与FIFO相关的代码。尤其是当要连接的端口数量众多时,这个缺点更加明显。
使用端口数组的情况,FIFO要优于IMP
假如参考模型中有16个类似端口要和scoreboard中相应的端口相互通信,如此多数量的端口,在参考模型中可以使用端口数组来实现:
|
|
-
使用 IMP 方式
如果连接关系使用IMP加后缀的方式,那么在scoreboard中的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38文件:src/ch4/section4.3/4.3.5/imp/my_scoreboard.sv `uvm_analysis_imp_decl(_model0) … `uvm_analysis_imp_decl(_modelf) `uvm_analysis_imp_decl(_monitor) class my_scoreboard extends uvm_scoreboard; my_transaction expect_queue[$]; uvm_analysis_imp_monitor#(my_transaction, my_scoreboard) monitor_imp; uvm_analysis_imp_model0#(my_transaction, my_scoreboard) model0_imp; … uvm_analysis_imp_modelf#(my_transaction, my_scoreboard) modelf_imp; `uvm_component_utils(my_scoreboard) extern function new(string name, uvm_component parent = null); extern virtual function void build_phase(uvm_phase phase); extern virtual task main_phase(uvm_phase phase); extern function void write_monitor(my_transaction tr); extern function void write_model0(my_transaction tr); … extern function void write_modelf(my_transaction tr); endclass … function void my_scoreboard::build_phase(uvm_phase phase); super.build_phase(phase); monitor_imp = new("monitor_imp", this); model0_imp = new("model0_imp", this); … modelf_imp = new("modelf_imp", this); endfunction function void my_scoreboard::write_model0(my_transaction tr); expect_queue.push_back(tr); endfunction … function void my_scoreboard::write_modelf(my_transaction tr); expect_queue.push_back(tr); endfunction function void my_scoreboard::write_monitor(my_transaction tr); … endfunction并且在env中,需要:
1 2 3 4 5 6 7 8 9 10 11 12文件:src/ch4/section4.3/4.3.5/imp/my_env.sv function void my_env::connect_phase(uvm_phase phase); super.connect_phase(phase); i_agt.ap.connect(agt_mdl_fifo.analysis_export); mdl.port.connect(agt_mdl_fifo.blocking_get_export); o_agt.ap.connect(scb.monitor_imp); mdl.ap[0].connect(scb.model0_imp); mdl.ap[1].connect(scb.model1_imp); … mdl.ap[14].connect(scb.modele_imp); mdl.ap[15].connect(scb.modelf_imp); endfunction在如上列出的代码中使用了很多省略号,但是即使这样,相信读者也能感受到其中代码的冗余到了多么严重的程度。这一切都是因为ap与imp直接相连而不能使用for循环引起的
-
使用FIFO
scoreboard 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29文件:src/ch4/section4.3/4.3.5/fifo/my_scoreboard.sv class my_scoreboard extends uvm_scoreboard; my_transaction expect_queue[$]; uvm_blocking_get_port #(my_transaction) exp_port[16]; uvm_blocking_get_port #(my_transaction) act_port; … endclass … function void my_scoreboard::build_phase(uvm_phase phase); super.build_phase(phase); for(int i = 0; i < 16; i++) exp_port[i] = new($sformatf("exp_port_%0d", i), this); act_port = new("act_port", this); endfunction task my_scoreboard::main_phase(uvm_phase phase); … for(int i = 0; i < 16; i++) fork automatic int k = i; while (1) begin exp_port[k].get(get_expect); expect_queue.push_back(get_expect); end join_none while (1) begin act_port.get(get_actual); … end endtask在env中也可以使用for循环:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27文件:src/ch4/section4.3/4.3.5/fifo/my_env.sv class my_env extends uvm_env; … uvm_tlm_analysis_fifo #(my_transaction) agt_scb_fifo; uvm_tlm_analysis_fifo #(my_transaction) agt_mdl_fifo; uvm_tlm_analysis_fifo #(my_transaction) mdl_scb_fifo[16]; … virtual function void build_phase(uvm_phase phase); … agt_scb_fifo = new("agt_scb_fifo", this); agt_mdl_fifo = new("agt_mdl_fifo", this); for(int i = 0; i < 16; i++) mdl_scb_fifo[i] = new($sformatf("mdl_scb_fifo_%0d", i), this); endfunction … endclass function void my_env::connect_phase(uvm_phase phase); super.connect_phase(phase); i_agt.ap.connect(agt_mdl_fifo.analysis_export); mdl.port.connect(agt_mdl_fifo.blocking_get_export); for(int i = 0; i < 16; i++) begin mdl.ap[i].connect(mdl_scb_fifo[i].analysis_export); scb.exp_port[i].connect(mdl_scb_fifo[i].blocking_get_export); end o_agt.ap.connect(agt_scb_fifo.analysis_export); scb.act_port.connect(agt_scb_fifo.blocking_get_export); endfunction无论使用FIFO还是使用IMP,都能实现同样的目标,两者各有其优势与劣势。在实际应用中,读者可以根据自己的习惯来选择合适的连接方式。
UVM 中更简洁的FIFO通信方式( 只需要一组 uvm_tlm_analysis_fifo 和 uvm_analysis_port )
这种通信方式是在opentitan 的源码中抄的, opentitan 默认是基于UVM1.2 来运行的, 经过实验, 在UVM1.1 中也能用
scoreboard
|
|
在env 里连接
|
|
在 monitor 里发送
|
|
analysis_port 在 dv_base_monitor 里定义并例化
|
|
简单总结
- 在scoreboard 中声明并实例化一个 uvm_tlm_analysis_fifo 类型的 fifo, 然后使用 fifo.get(item) 从fifo 中获取数据
- 在 monitor 中声明并实例化一个 uvm_analysis_port 类型的 analysis_port, 使用 analysis_port.write(item); 来往FIFO 写数据
- 在 env 中把monitor 和 scoreboard 连接起来
1agent.monitor.analysis_port.connect(scoreboard.xxx_fifo.analysis_export);