callback 机制
在UVM验证平台中, callback机制的最大用处就是提高验证平台的可重用性。 很多情况下, 验证人员期望在一个项目中开发
的验证平台能够用于另外一个项目。 但是, 通常来说, 完全的重用是比较难实现的, 两个不同的项目之间或多或少会有一些差
异。 如果把两个项目不同的地方使用callback函数来做, 而把相同的地方写成一个完整的env, 这样重用时, 只要改变相关的
callback函数env可完全的重用。
除了提高可重用性外, callback机制还用于构建异常的测试用例
广义的callback函数
post_randomize就是SystemVerilog提供的一个callback函数, 当randomize( ) 之后, 系统会自动调用post_randomize
只需要重载系统的 post_randomize 就可以实现自定义的功能
如示例:
|
|
这样在随机化 tr 之后就会自动调用 calc_crc 来产生crc 了
|
|
post_randomize函数是SystemVerilog提供的广义的callback函数。
UVM也为用户提供了广义的callback函数/任务: pre_body和 post_body, 除此之外还有pre_do、 mid_do和post_do。
callback机制的必要性
callback 机制使用户写程序更加自由, 而且可以使程序更简洁, 除此之外, callback 机制还可以用来构建异常测试用例
UVM中callback机制的原理
略
callback机制的使用
要实现真正的pre_tran, 需要首先定义上节所说的类A:
|
|
A类一定要从uvm_callback派生, 另外还需要定义一个pre_tran的任务, 此任务的类型一定要是 virtual 的, 因为从A派生的类需要重载这个任务
接下来声明一个A_pool类:
|
|
A_pool的声明相当简单, 只需要一个typedef语句即可。 另外, 在这个声明中除了要指明这是一个A类型的池子外, 还要指明这个池子将会被哪个类使用。
在本例中, my_driver将会使用这个池子, 所以要将此池子声明为my_driver专用的。 之后, 在my_driver中要做如下声明:
|
|
这个声明与A_pool的类似, 要指明my_driver和A。 在my_driver的main_phase中调用pre_tran时并不如上节所示的那么简单, 而
是调用了一个宏来实现:
|
|
uvm_do_callbacks宏的第一个参数是调用pre_tran的类的名字, 这里自然是my_driver, 第二个参数是哪个类具有pre_tran, 这里是A,
第三个参数是调用的是函数/任务, 这里是pre_tran, 在指明是pre_tran时, 要顺便给出pre_tran的参数。
到目前为止是VIP的开发者应该做的事情, 作为使用VIP的用户来说, 需要做如下事情:
首先从A派生一个类:
|
|
其次, 在测试用例中将my_callback实例化, 并将其加入A_pool中:
|
|
my_callback的实例化是在connect_phase中完成的, 实例化完成后需要将my_cb加入A_pool中。 同时, 在加入时需要指定是给哪个my_driver使用的。
因为很可能整个base_test中实例化了多个my_env, 从而有多个my_driver的实例, 所以要将my_driver的路径作为add函数的第一个参数。
至此, 一个简单的callback机制示例就完成了。
这个示例几乎涵盖UVM中所有可能用到的callback机制的知识, 大部分callback 机制的使用都与这个例子相似。
总结一下, 对于VIP的开发者来说, 预留一个callback函数/任务接口时需要做以下几步:
- 定义一个A类
- 声明一个A_pool类
- 在要预留callback函数/任务接口的类中调用uvm_register_cb宏
- 在要调用callback函数/任务接口的函数/任务中, 使用uvm_do_callbacks宏
对于VIP的使用者来说, 需要做如下几步:
- 从A派生一个类, 在这个类中定义好pre_tran
- 在测试用例的connect_phase(或者其他phase, 但是一定要在使用此callback函数/任务的phase之前) 中将从A派
生的类实例化, 并将其加入A_pool中
本节的my_driver是自己写的, my_case0也是自己写的。 完全不存在VIP与VIP使用者的情况。 不过换个角度来说, 可能有两个
验证人员共同开发一个项目, 一个负责搭建测试平台( testbench) 及my_driver等的代码, 另外一位负责创建测试用例。 负责搭建
测试平台的验证人员为搭建测试用例的人员留下了callback函数/任务接口。 即使my_driver与测试用例都由同一个人来写, 也是完
全可以接受的。 因为不同的测试用例肯定会引起不同的driver的行为。 这些不同的行为差异可以在sequence中实现, 也可以在driver
中实现。 在driver中实现时既可以用driver的factory机制重载, 也可以使用本节所讲的callback机制。 后续将探讨只使用callback机
制来搭建所有测试用例的可能。
子类继承父类的callback机制
使用uvm_set_super_type宏, 它把子类和父类关联在一起。 其第一个参数是子类, 第二个参数是父类。
在main_phase中调用uvm_do_callbacks宏时, 其第一个参数是my_driver, 而不是new_driver, 即调用方式与在my_driver中一样。
|
|
在my_agent中实例化此new_driver:
|
|
这样, 上节中的my_case0不用经过任何修改就可以在新的验证平台上通过。
使用callback函数/任务来实现所有的测试用例
假设A类定义如下:
|
|
在my_driver的main_phase中, 去掉所有其他代码, 只调用A的run:
|
|
在建立新的测试用例时, 只需要从A派生一个类, 并重载其gen_tran函数:
|
|
输出结果为:
|
|
在这种情况下, 新建测试用例相当于重载gen_tran。 如果不满足要求, 还可以将A类的run任务重载。
在这个示例中完全丢弃了sequence机制, 在A类的run任务中进行控制objection, 激励产生在gen_tran中。
callback机制、 sequence机制和factory机制
callback机制、 sequence机制和factory机制在某种程度上来说很像: 它们都能实现搭建测试用例的目的。 只是sequence机制是 UVM一直提倡的生成激励的方式,
UVM为此做了大量的工作, 如构建了许多宏、 嵌套的sequence、 virtual sequence、 可重用性等
虽然callback机制能够实现所有的测试用例, 但是某些测试用例用 sequence来实现则更加方便。 virtual sequence的协调功能在callback机制中就很难实现
callback机制、 sequence机制和factory机制并不是互斥的, 三者都能分别实现同一目的。 当这三者互相结合时, 又会产生许多新的解决问题的方式。 如果在建立验证平台和测试用例时, 能够择优选择其中最简单的一种实现方式, 那么搭建出来的验证平台一定是足够强大、 足够简练的。 实现同一事情有多种方式, 为用户提供了多种选择, 高扩展性是UVM取得成功的一个重要原因。
功能的模块化
模块要小而美
避免重复的代码
同样的代码只在验证平台上出现一处, 如果要重用, 将它们封装成可重载的函数/任务或者类
放弃建造强大sequence的想法
UVM的sequence功能非常强大, 很多用户喜欢将他们的sequence写得非常完美, 他们的目的是建造通用的sequence, 有些用户
甚至执着于一个sequence解决验证平台中所有的问题, 在使用时, 只需要配置参数即可。
sequence 写得太复杂有以下两点不好:
第一, 这个sequence的代码量非常大, 分支众多, 后期维护相当麻烦。 如果代码编写者与维护者不是同一个人, 那么对于维
护者来说, 简直就是灾难。 即使代码编写者与维护者是同一个人, 那么在一段时间之后, 自己也可能被自己以前写的东西感到迷
惑不已。
第二, 使用这个sequence的人面对如此多的参数, 他要如何选择呢? 他有时只想使用其中最基本的一个功能, 但是却不知道
怎么配置, 只能所有的参数都看一遍。 如果看一遍能看懂还好, 但是有时候即使看两三遍也看不懂.
如果用户非常坚持上述超级强大的sequence, 那么请一定要做到以下两点之一:
· 有一份完整的文档介绍它
· 有较多的代码注释
参数化的类
相比普通的类, 参数化的类在定义时会有些复杂, 其古怪的语法可能会使人望而却步。 并不是说所有的类一定要定义成参数
化的类。 对于很多类来说, 根本没有参数可言, 如果定义成参数化的类, 根本没有任何优势可言。 所以, 定义成参数化的类的前
提是, 这个参数是有意义的、 可行的。 2.3.1节的my_transaction是没有任何必要定义成一个参数化的类的。 相反, 一个总线
transaction 可能需要定义成参数化的类, 因为总线位宽可能是16位的、 32位的或64位的。
UVM对参数化类的支持
UVM对参数化类的支持首先体现在factory机制注册上。 uvm_object_param_utils和 uvm_component_param_utils
这两个用于参数化的object和参数化的component注册的宏。
UVM的config_db机制可以用于传递virtual interface。 SystemVerilog支持参数化的interface:
|
|
config_db机制同样支持传递参数化的interface:
|
|
sequence机制同样支持参数化的transaction:
|
|
很多参数化的类都有默认的参数, 用户在使用时经常会使用默认的参数。 但是UVM的factory机制不支持参数化类中的默认参
数。 换言之, 假如有如下的agent定义:
|
|
在声明agent时可以按照如下写法来省略参数:
|
|
但是在实例化时, 必须将省略的参数加上 :
|
|
模块级到芯片级的代码重用
假设有如下集成在芯片中的三个模块需要验证
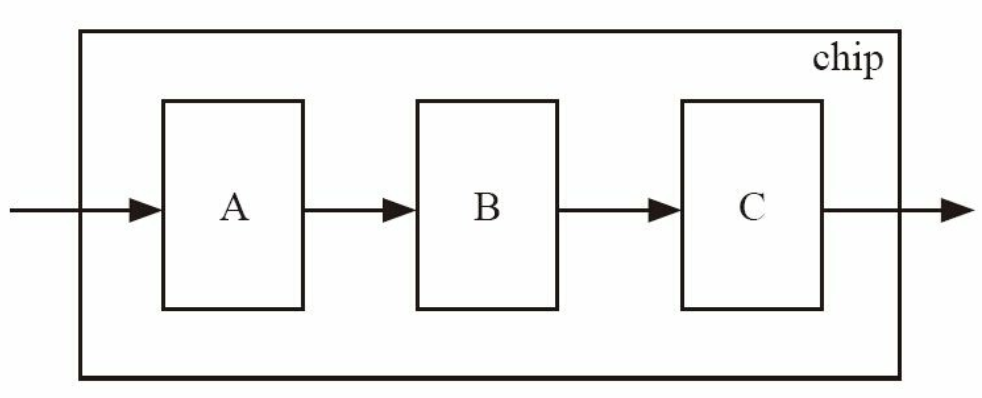
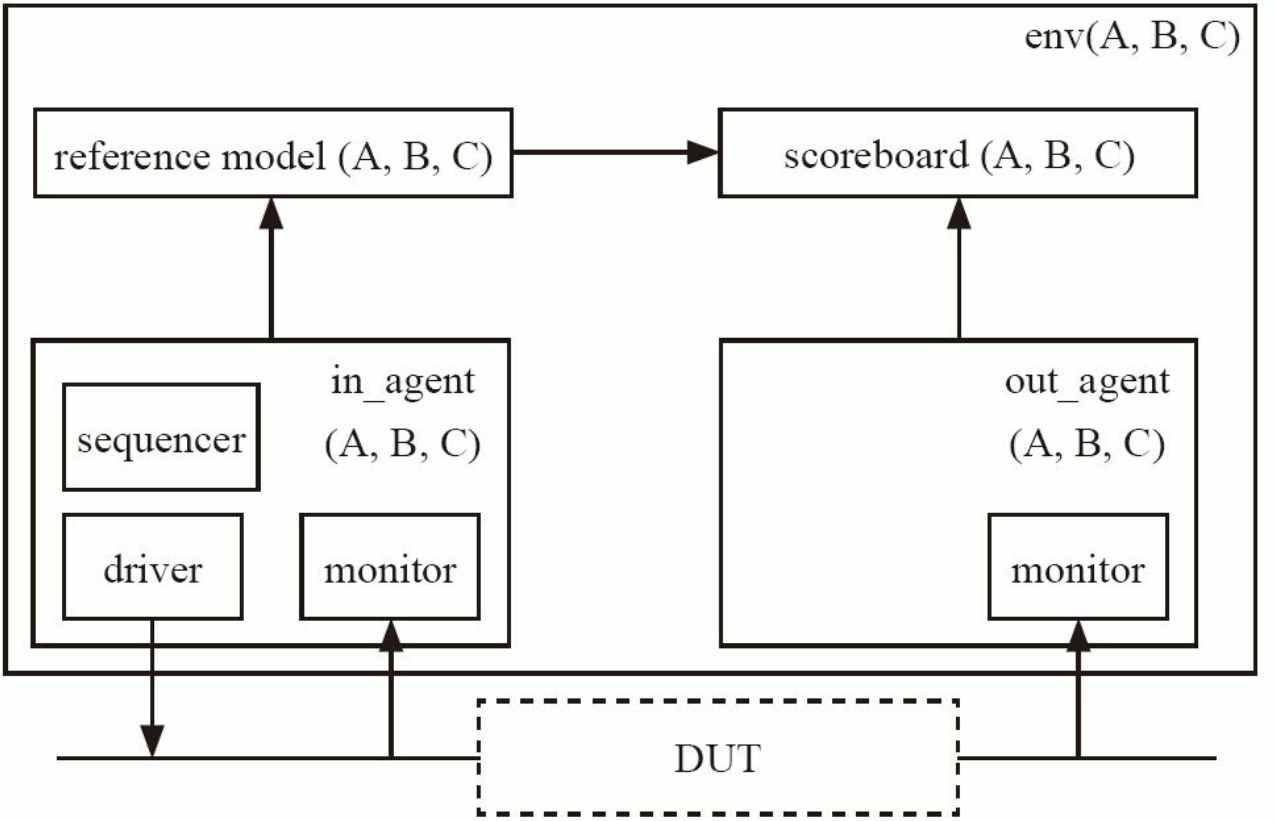
这三个模块在验证时分别有自己的 driver 和 sequencer
采用 env 级别的重用
那么B和C中的driver分别取消, 这可以通过设置各自i_agt的is_active来控制
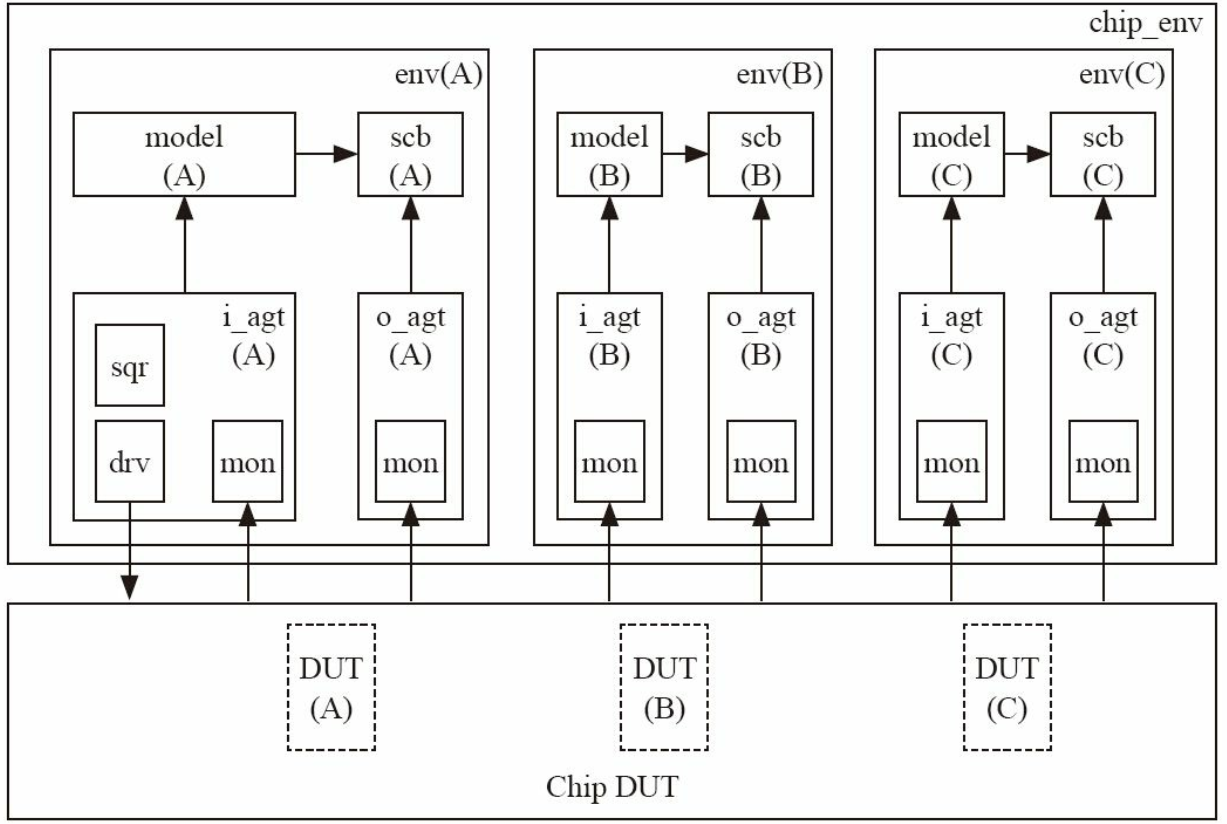
采用芯片级别的重用
仔细观察 采用 env 级别的重用 发现o_agt( A) 和i_agt( B) 两者监测的是同一接口, 换言之, 二者应该是同一个agent。 在模块级别验证
时, i_agt( B) 被配置为active模式, 在下图中被配置为passive模式。 被配置为passive模式的i_agt( B) 其实和o_agt( A) 完全一
样, 二者监测同一接口, 对外发出同样的transaction。 或者说, 其实可以将i_agt( B) 取消, model( B) 的数据来自o_agt( A) 。
o_agt( B) 和i_agt( C) 也是同样的情况
取消了i_agt( B) 和i_agt( C) 的芯片级别验证平台如下图所示:

在验证平台中, 每个模块验证环境需要在其env中添加一个analysis_port用于数据输出; 添加一个analysis_export用于数据输入;
在env中设置in_chip用于辨别不同的数据来源:
|
|
在chip_env中, 实例化env_A、 env_B、 env_C, 将env_B和env_C的in_chip设置为1, 并将env_A的ap口与env_B的i_export相连,
将env_B的ap与env_C的i_export相连接:
|
|
两种重用对比
重用env 的验证平台中, 各个env之间没有数据交互, 从而各个env不必设置analysis_port及analysis_export, 在连接上简单些。
芯片级别的重用中, 整个验证平台中消除了冗余的monitor, 这在一定程度上可以加快仿真速度. 不同模块的验证环境之间有数据交互时, 可以互相检查对方接口数据是否合乎规范。 如A的数据送给了B, 而B无法正常工
作, 那么要么是A收集的数据是错的, 不符合B的要求, 要么就是A收集的数据是对的, 但是B对接口数据理解有误
寄存器模型的重用
bus_agt是作为env的一部分的。 如下图所示的env 是不可重用的。
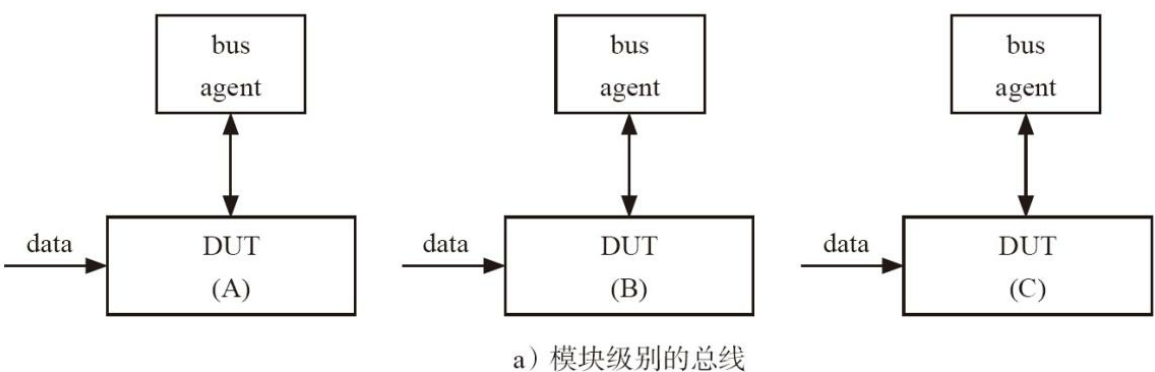
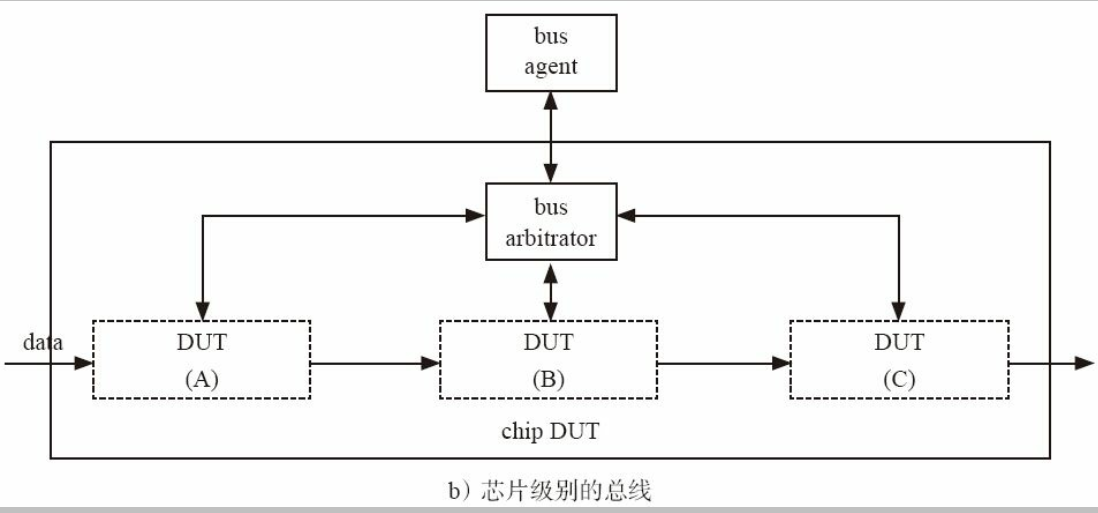
因此, 为了提高可重用性, 在模块级别时, bus_agt应该从env中移到base_test中

与bus_agt对应的是寄存器模型。 在模块级别验证时, 每个模块有各自的寄存器模型。 很多用户习惯于在env中实例化寄存器模型:
|
|
但是如果要实现env级别的重用, 是不能在env中实例化寄存器模型的。 每个模块都有各自的偏移地址, 如A的偏移地址可能
是’h0000, 而B的偏移地址是’h4000, C的偏移地址是’h8000( 即16位地址的高两位用于辨识不同模块) 。 如果在env级别例化了寄
存器模型, 那么在芯片级时, 是不能指定其偏移地址的。
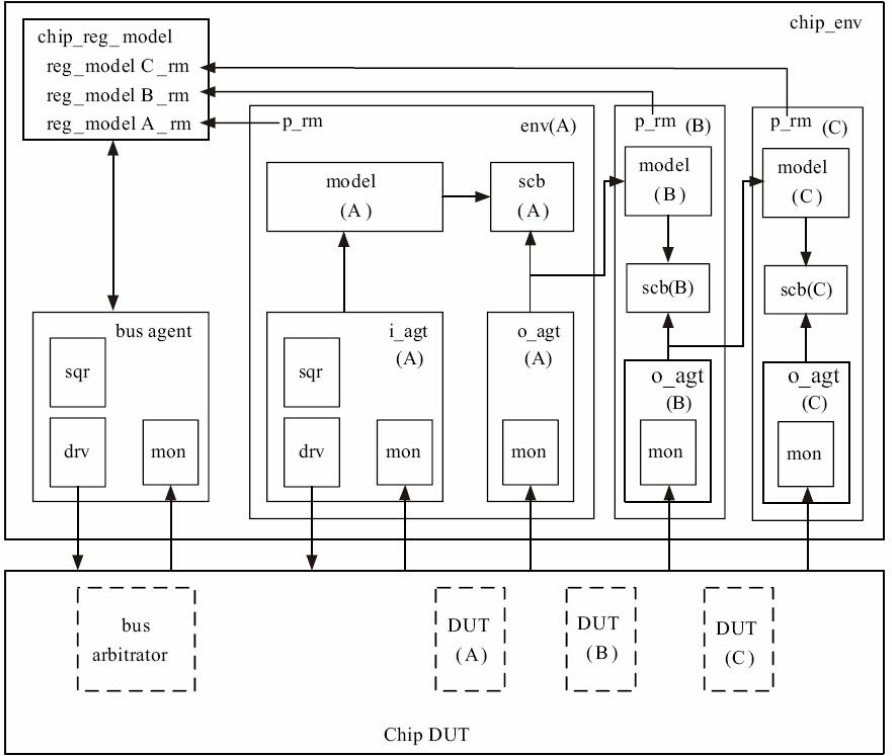
因此, 在模块级别验证时, 需要在base_test中实例化寄存器模型, 在env中设置一个寄存器模型的指针, 在base_test中对它赋值。
为了在芯片级别使用寄存器模型, 需要建立一个新的寄存器模型:
|
|
这个新的寄存器模型中只需要加入各个不同模块的寄存器模型并设置偏移地址和后门访问路径。
在chip_env中实例化此寄存器模型, 并将各个模块的寄存器模型的指针赋值给各个env的p_rm:
|
|
加入寄存器模型后, 整个验证平台的框图变为下图
virtual sequence与virtual sequencer
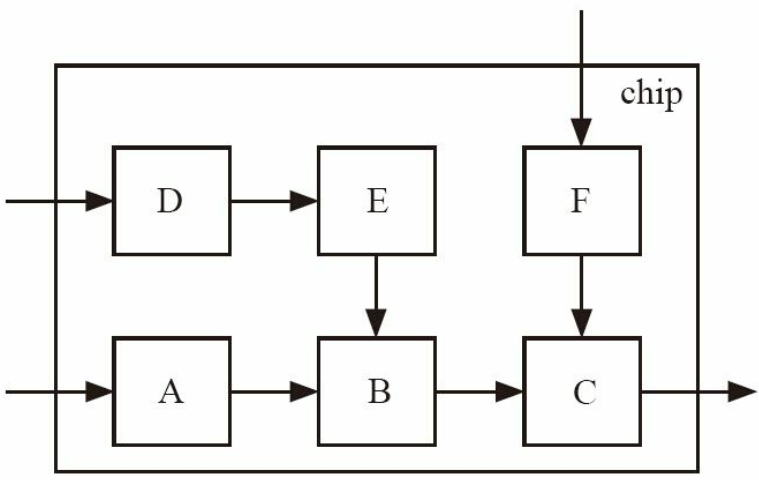
A 、 D和F分别是边界输入模块。 在整个芯片的virtual sequencer中, 应该包含A、 D和F的sequencer。 因此A、 D和F的virtual sequencer是不能直接用于芯片级验证的。 无论是像B、 C、 E这样的内部模块还是A、 D、 F这样的边界输入模块, 统一推荐其virtual sequencer在base_test中实例化。 在芯片级别建立自己的virtual sequencer。
与virtual sequencer相对应的是virtual sequence, 通常来说, virtual sequence都使用uvm_declare_p_sequencer宏来指定sequencer。
这些sequencer在模块级别是存在的, 但是在芯片级根本不存在, 所以这些virtual sequence无法用于芯片级别验证。
两种模块级别的sequence可以直接用于芯片级别的验证的方法
-
一种如A、 D和F这样的边界输入端的是普通的sequence( 不是virtual sequence)
以A的某sequence为例, 在模块级别可以这样使用它:
1 2 3 4 5 6 7class A_vseq extends uvm_sequence; virtual task body(); A_seq aseq; `uvm_do_on(aseq, p_sequencer.p_sqr) … endtask endclass在芯片级别这样使用它:
1 2 3 4 5 6 7 8 9 10 11 12 13class chip_vseq extends uvm_sequence; virtual task body(); A_seq aseq; D_seq dseq; F_seq fseq; fork `uvm_do_on(aseq, p_sequencer.p_a_sqr) `uvm_do_on(aseq, p_sequencer.p_d_sqr) `uvm_do_on(aseq, p_sequencer.p_f_sqr) join … endtask endclass
-
另外一种是寄存器配置的sequence。
这种sequence一般在定义时不指定transaction类型。 如果这些sequence做成如下的形式, 也是无法重用的:
1 2 3 4 5 6class A_cfg_seq extends uvm_sequence; virtual task body(); p_sequencer.p_rm.xxx.write(); … endtask endclass要想能够在芯片级别重用, 需要使用如下的方式定义:
1 2 3 4 5 6 7class A_cfg_seq extends uvm_sequence; A_reg_model p_rm; virtual task body(); p_rm.xxx.write(); … endtask endclass在模块级别以如下的方式启动它:
1 2 3 4 5 6 7 8class A_vseq extends uvm_sequence; virtual task body(); A_cfg_seq c_seq; c_seq = new("c_seq"); c_seq.p_rm = p_sequencer.p_rm; c_seq.start(null); endtask endclass在芯片级别以如下的方式启动:
1 2 3 4 5 6 7 8 9class chip_vseq extends uvm_sequence; virtual task body(); A_cfg_seq A_c_seq; A_c_seq = new("A_c_seq"); A_c_seq.p_rm = p_sequencer.p_rm.A_rm; A_c_seq.start(null); … endtask endclass除了这种指针传递的形式外, 还可以通过get_root_blocks来获得。 在芯片级时, root block已经和模块级别不同,
单纯靠get_root_blocks已经无法满足要求。 此时需要find_blocks、 find_block、 get_blocks和get_block_by_name等函数,
这里不再一一介绍。