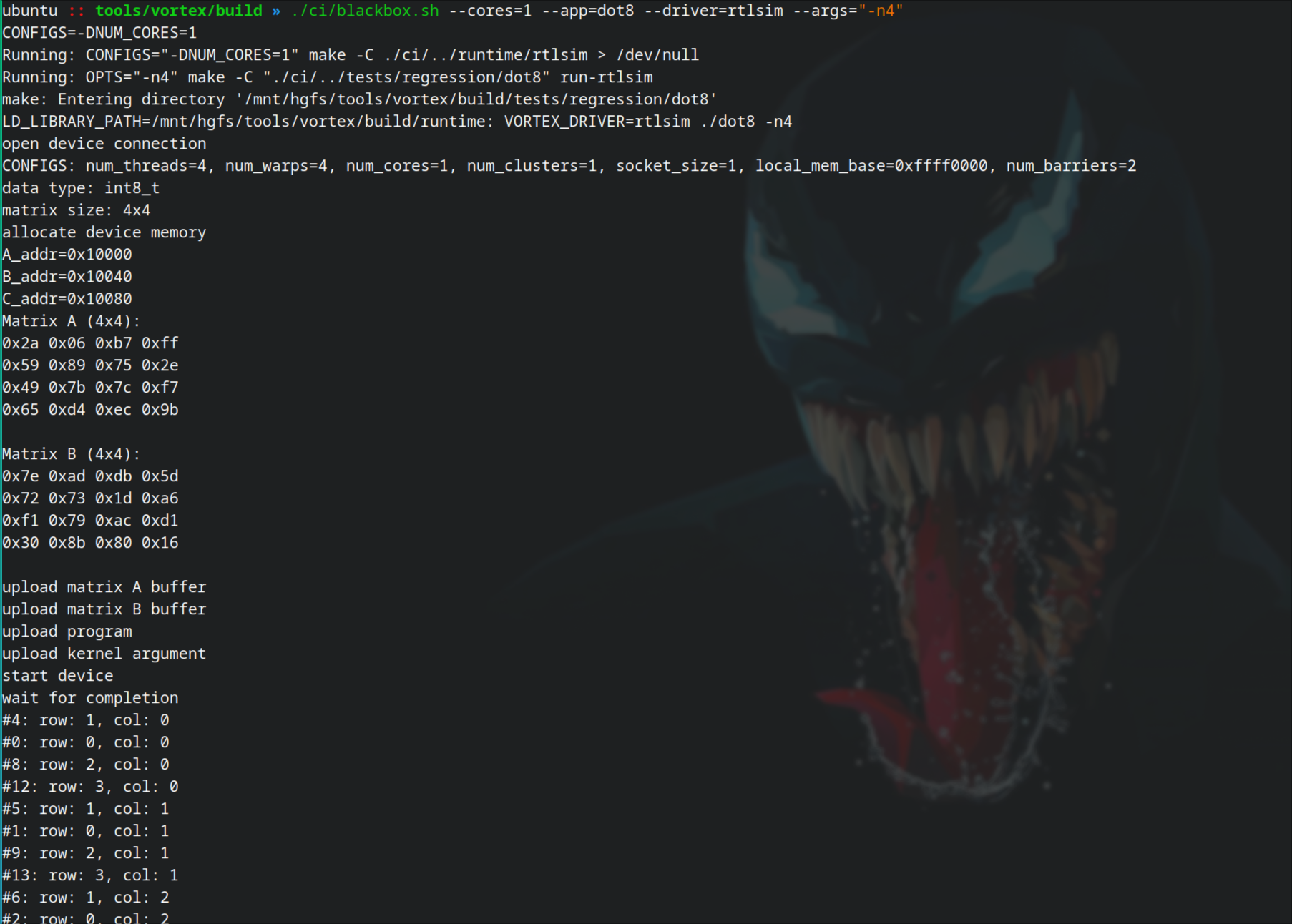
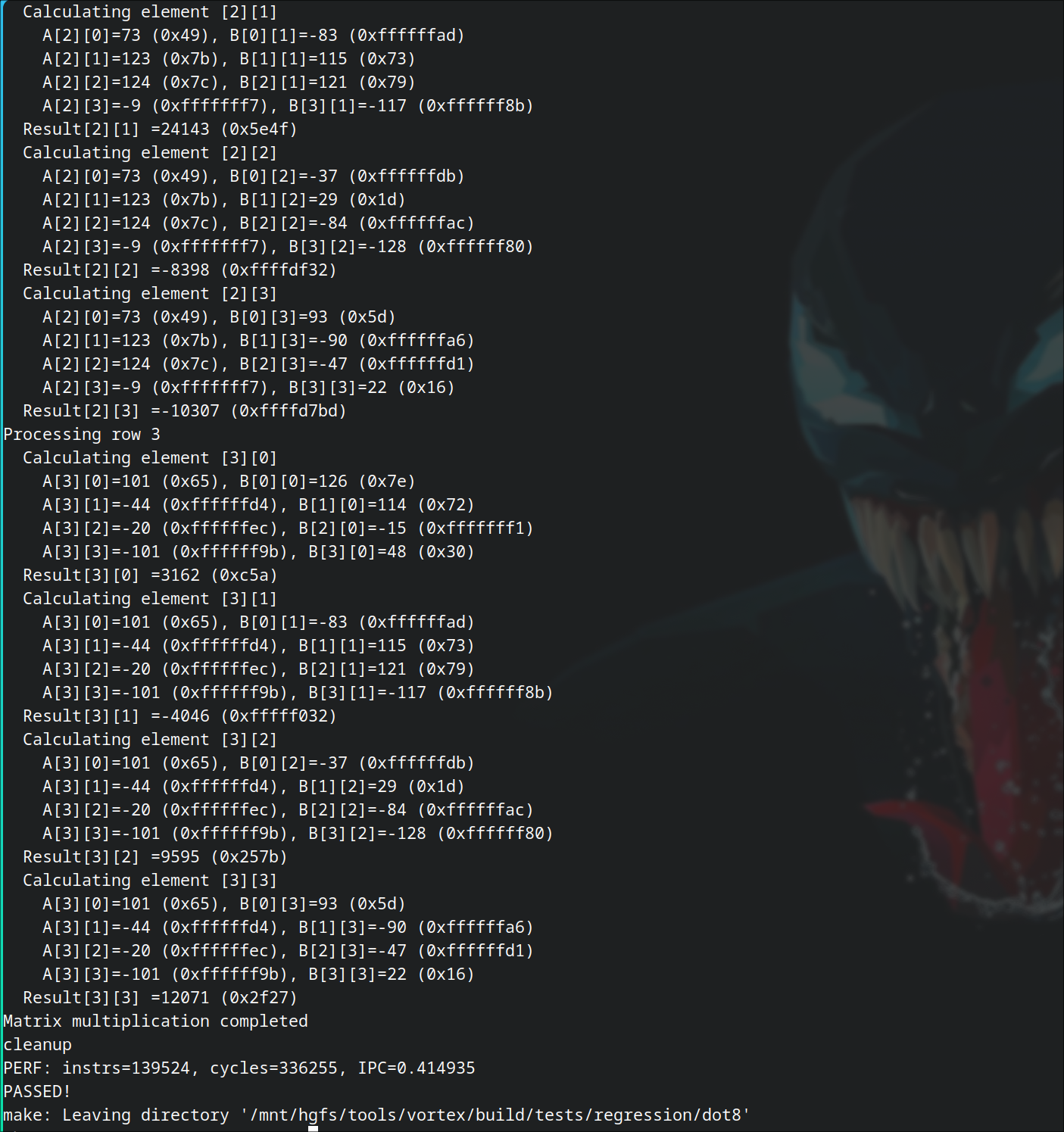
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
877
878
879
880
|
diff --git a/ci/toolchain_env.sh.in b/ci/toolchain_env.sh.in
index 9c3387c1..07678ee8 100755
--- a/ci/toolchain_env.sh.in
─+++ b/ci/toolchain_env.sh.in
@@ -16,6 +16,7 @@
TOOLDIR=${TOOLDIR:=@TOOLDIR@}
export PATH=$TOOLDIR/verilator/bin:$PATH
+export PATH=$TOOLDIR/llvm-vortex/bin:$PATH
export SV2V_PATH=$TOOLDIR/sv2v
export PATH=$SV2V_PATH/bin:$PATH
diff --git a/hw/rtl/VX_config.vh b/hw/rtl/VX_config.vh
index a6d2819c..ba039e3b 100644
--- a/hw/rtl/VX_config.vh
+++ b/hw/rtl/VX_config.vh
@@ -36,6 +36,10 @@
`define EXT_M_ENABLE
`endif
+`ifndef EXT_DOT8_DISABLE
+`define EXT_DOT8_ENABLE
+`endif
+
`ifndef EXT_F_DISABLE
`define EXT_F_ENABLE
`endif
@@ -501,6 +505,11 @@
`define LATENCY_FCVT 5
`endif
+// DOT8 Latency
+`ifndef LATENCY_DOT8
+`define LATENCY_DOT8 2
+`endif
+
// FMA Bandwidth ratio
`ifndef FMA_PE_RATIO
`define FMA_PE_RATIO 1
@@ -884,6 +893,12 @@
`define EXT_M_ENABLED 0
`endif
+`ifdef EXT_DOT8_ENABLE
+ `define EXT_DOT8_ENABLED 1
+`else
+ `define EXT_DOT8_ENABLED 0
+`endif
+
`ifdef EXT_V_ENABLE
`define EXT_V_ENABLED 1
`else
diff --git a/hw/rtl/VX_gpu_pkg.sv b/hw/rtl/VX_gpu_pkg.sv
index f2f00ed7..bdecfa98 100644
--- a/hw/rtl/VX_gpu_pkg.sv
+++ b/hw/rtl/VX_gpu_pkg.sv
@@ -183,6 +183,7 @@ package VX_gpu_pkg;
localparam INST_ALU_ADD = 4'b0000;
//localparam INST_ALU_UNUSED=4'b0001;
+ localparam INST_ALU_DOT8=4'b0001;
localparam INST_ALU_LUI = 4'b0010;
localparam INST_ALU_AUIPC = 4'b0011;
localparam INST_ALU_SLTU = 4'b0100;
diff --git a/hw/rtl/core/VX_alu_dot8.sv b/hw/rtl/core/VX_alu_dot8.sv
new file mode 100644
index 00000000..0a9f5998
--- /dev/null
+++ b/hw/rtl/core/VX_alu_dot8.sv
@@ -0,0 +1,108 @@
+// ********************************************************************************
+// Copyright © 2025 Wcq
+// File Name: VX_alu_dot8.sv
+// Author: Wcq
+// Email: wcq-062821@163.com
+// Created: 2025-06-10 15:52:49
+// Last Update: 2025-08-11 12:45:43
+// By: Wcq
+// Description:
+// ********************************************************************************
+`include "VX_define.vh"
+
+module VX_alu_dot8 import VX_gpu_pkg::*; #(
+ parameter `STRING INSTANCE_ID = "",
+ parameter NUM_LANES = 1
+) (
+ input wire clk,
+ input wire reset,
+
+ // Inputs
+ VX_execute_if.slave execute_if,
+
+ // Outputs
+ VX_result_if.master result_if
+);
+ `UNUSED_SPARAM (INSTANCE_ID)
+ localparam PID_BITS = `CLOG2(`NUM_THREADS / NUM_LANES);
+ localparam PID_WIDTH = `UP(PID_BITS);
+ localparam TAG_WIDTH = UUID_WIDTH + NW_WIDTH + NUM_LANES + PC_BITS + NUM_REGS_BITS + 1 + PID_WIDTH + 1 + 1;
+ localparam LATENCY_DOT8 = `LATENCY_DOT8;
+ localparam PE_RATIO = 2;
+ localparam NUM_PES = `UP(NUM_LANES / PE_RATIO);
+ // localparam MUL_LATENCY = 1;
+
+ `UNUSED_VAR (execute_if.data.op_type)
+ `UNUSED_VAR (execute_if.data.rs3_data)
+
+ wire [NUM_LANES-1:0][2*`XLEN-1:0] data_in;
+
+ for (genvar i = 0; i < NUM_LANES; ++i) begin : g_dot8_lanes
+ assign data_in[i][0 +: `XLEN] = execute_if.data.rs1_data[i];
+ assign data_in[i][`XLEN +: `XLEN] = execute_if.data.rs2_data[i];
+ end
+
+ wire pe_enable;
+ wire [NUM_PES-1:0][2*`XLEN-1:0] pe_data_in;
+ wire [NUM_PES-1:0][`XLEN-1:0] pe_data_out;
+
+ // PEs time-multiplexing
+ VX_pe_serializer #(
+ .NUM_LANES (NUM_LANES),
+ .NUM_PES (NUM_PES),
+ .LATENCY (LATENCY_DOT8),
+ .DATA_IN_WIDTH (2*`XLEN),
+ .DATA_OUT_WIDTH (`XLEN),
+ .TAG_WIDTH (TAG_WIDTH),
+ .PE_REG (1)
+ ) pe_serializer (
+ .clk (clk),
+ .reset (reset),
+ .valid_in (execute_if.valid),
+ .data_in (data_in),
+ .tag_in ({
+ execute_if.data.uuid,
+ execute_if.data.wid,
+ execute_if.data.tmask,
+ execute_if.data.PC,
+ execute_if.data.rd,
+ execute_if.data.wb,
+ execute_if.data.pid,
+ execute_if.data.sop,
+ execute_if.data.eop
+ }),
+ .ready_in (execute_if.ready),
+ .pe_enable (pe_enable),
+ .pe_data_in (pe_data_out),
+ .pe_data_out(pe_data_in),
+ .valid_out (result_if.valid),
+ .data_out (result_if.data.data),
+ .tag_out ({
+ result_if.data.uuid,
+ result_if.data.wid,
+ result_if.data.tmask,
+ result_if.data.PC,
+ result_if.data.rd,
+ result_if.data.wb,
+ result_if.data.pid,
+ result_if.data.sop,
+ result_if.data.eop
+ }),
+ .ready_out (result_if.ready)
+ );
+
+ // PEs instancing
+ for (genvar i = 0; i < NUM_PES; ++i) begin : g_dot8
+ wire [31:0] a = pe_data_in[i][0 +: 32]; // rs1
+ wire [31:0] b = pe_data_in[i][32 +: 32]; // rs2
+ // TODO:
+ //
+ wire [31:0] c = signed'(8'(a[7:0])) * signed'(8'(b[7:0])) + signed'(8'(a[15:8])) * signed'(8'(b[15:8]))
+ + signed'(8'(a[23:16])) * signed'(8'(b[23:16])) + signed'(8'(a[31:24])) * signed'(8'(b[31:24]));
+
+ wire [31:0] result;
+ `BUFFER_EX(result, c, pe_enable, 1, LATENCY_DOT8);
+ assign pe_data_out[i] = result;
+ end
+
+endmodule
diff --git a/hw/rtl/core/VX_alu_int.sv b/hw/rtl/core/VX_alu_int.sv
index 88602d0d..4f1af025 100644
--- a/hw/rtl/core/VX_alu_int.sv
+++ b/hw/rtl/core/VX_alu_int.sv
@@ -213,14 +213,21 @@ module VX_alu_int import VX_gpu_pkg::*; #(
// branch
- wire [PC_BITS-1:0] PC_r;
- wire [INST_BR_BITS-1:0] br_op_r;
- wire [PC_BITS-1:0] cbr_dest, cbr_dest_r;
- wire [LANE_WIDTH-1:0] last_tid, last_tid_r;
- wire is_br_op_r;
assign cbr_dest = from_fullPC(add_result[0]);
+ wire [PC_BITS-1:0] PC_r; // 延迟后的程序计数器值,用于分支指令的返回地址计算
+ wire [INST_BR_BITS-1:0] br_op_r; // 延迟后的分支操作码,指示具体的分支指令类型
+ wire [PC_BITS-1:0] cbr_dest, cbr_dest_r; // 条件分支的目标地址,从加法结果中提取, 以及延迟后的目标地址
+ wire [LANE_WIDTH-1:0] last_tid, last_tid_r; // 当前线程在通道内的ID, 延迟后的线程ID
+ wire is_br_op_r; // 延迟后的分支操作标志位
+
+ // assign cbr_dest = add_result[0][1 +: `PC_BITS]; // 从位1开始提取PC_BITS` 位,这是因为RISC-V指令地址必须是2字节对齐的(最低位始终为0)
+ assign cbr_dest = from_fullPC(add_result[0]); // 从位1开始提取PC_BITS` 位,这是因为RISC-V指令地址必须是2字节对齐的(最低位始终为0)
+ // 当 LANE_BITS != 0 时:从执行接口的线程ID中提取低 LANE_BITS 位作为通道内的线程ID
+ // 当 LANE_BITS == 0 时:直接将线程ID设为0,表示只有单个通道
+
+
if (LANE_BITS != 0) begin : g_last_tid
VX_priority_encoder #(
.N (NUM_LANES),
@@ -249,21 +256,26 @@ module VX_alu_int import VX_gpu_pkg::*; #(
);
`UNUSED_VAR (br_op_r)
- wire is_br_neg = inst_br_is_neg(br_op_r);
- wire is_br_less = inst_br_is_less(br_op_r);
- wire is_br_static = inst_br_is_static(br_op_r);
+ wire is_br_neg = inst_br_is_neg(br_op_r); // 判断是否为否定分支(如BNE、BGE等)
+ wire is_br_less = inst_br_is_less(br_op_r); // 判断是否为小于比较分支(如BLT、BLTU等)
+ wire is_br_static = inst_br_is_static(br_op_r); // 判断是否为静态分支(如JAL、JALR等)
+
+ wire [`XLEN-1:0] br_result = alu_result_r[last_tid_r]; // 从对应线程的ALU结果中提取比较结果
+ wire is_less = br_result[0]; // 第0位表示小于比较的结果
+ wire is_equal = br_result[1]; // 第1位表示相等比较的结果
- wire [`XLEN-1:0] br_result = alu_result_r[last_tid_r];
- wire is_less = br_result[0];
- wire is_equal = br_result[1];
wire result_fire = result_if.valid && result_if.ready;
wire br_enable = result_fire && is_br_op_r && result_if.data.eop;
- wire br_taken = ((is_br_less ? is_less : is_equal) ^ is_br_neg) | is_br_static;
+
+ wire br_taken = ((is_br_less ? is_less : is_equal) ^ is_br_neg) | is_br_static; // 根据 is_br_less 选择使用小于或相等比较结果, 通过异或 is_br_neg 处理否定分支, 静态分支(is_br_static)总是跳转
+
+ // 静态分支 => 目标地址从ALU结果中提取(如JALR指令) 条件分支 => 使用预计算的分支目标地址 cbr_dest_r
wire [PC_BITS-1:0] br_dest = is_br_static ? from_fullPC(br_result) : cbr_dest_r;
wire [NW_WIDTH-1:0] br_wid;
`ASSIGN_BLOCKED_WID (br_wid, result_if.data.wid, BLOCK_IDX, `NUM_ALU_BLOCKS)
+ // 分支控制信息通过流水线寄存器传递给调度器, 这确保了分支控制信号与流水线时序同步
VX_pipe_register #(
.DATAW (1 + NW_WIDTH + 1 + PC_BITS),
.RESETW (1)
@@ -275,6 +287,8 @@ module VX_alu_int import VX_gpu_pkg::*; #(
.data_out ({branch_ctl_if.valid, branch_ctl_if.wid, branch_ctl_if.taken, branch_ctl_if.dest})
);
+ // 对于静态分支指令,需要将返回地址写入目标寄存器, 返回地址计算为 PC_r + 2(下一条指令地址),最低位设为0确保地址对齐
+ // PC值在内部存储时通常省略这个最低位以节省存储空间, 所以下面的PC_r + `PC_BITS'(2) 之后还会拼接一个 1'd0
for (genvar i = 0; i < NUM_LANES; ++i) begin : g_result
wire [`XLEN-1:0] PC_next = to_fullPC(PC_r) + `XLEN'(4);
assign result_if.data.data[i] = (is_br_op_r && is_br_static) ? PC_next : alu_result_r[i];
diff --git a/hw/rtl/core/VX_alu_unit.sv b/hw/rtl/core/VX_alu_unit.sv
index 1b7f9b63..c84cc3ed 100644
--- a/hw/rtl/core/VX_alu_unit.sv
+++ b/hw/rtl/core/VX_alu_unit.sv
@@ -31,10 +31,12 @@ module VX_alu_unit import VX_gpu_pkg::*; #(
localparam BLOCK_SIZE = `NUM_ALU_BLOCKS;
localparam NUM_LANES = `NUM_ALU_LANES;
localparam PARTIAL_BW = (BLOCK_SIZE != `ISSUE_WIDTH) || (NUM_LANES != `SIMD_WIDTH);
- localparam PE_COUNT = 1 + `EXT_M_ENABLED;
+ localparam PE_COUNT = 1 + `EXT_M_ENABLED + `EXT_DOT8_ENABLED;
+
localparam PE_SEL_BITS = `CLOG2(PE_COUNT);
localparam PE_IDX_INT = 0;
localparam PE_IDX_MDV = PE_IDX_INT + `EXT_M_ENABLED;
+ localparam PE_IDX_DOT8 = PE_IDX_INT + `EXT_M_ENABLED + `EXT_DOT8_ENABLED;
VX_execute_if #(
.data_t (alu_exe_t)
@@ -70,6 +72,9 @@ module VX_alu_unit import VX_gpu_pkg::*; #(
pe_select = PE_IDX_INT;
if (`EXT_M_ENABLED && (per_block_execute_if[block_idx].data.op_args.alu.xtype == ALU_TYPE_MULDIV))
pe_select = PE_IDX_MDV;
+ else if (`EXT_DOT8_ENABLED && (per_block_execute_if[block_idx].data.op_args.alu.xtype == ALU_TYPE_OTHER))
+ pe_select = PE_IDX_DOT8;
+
end
VX_pe_switch #(
@@ -111,6 +116,19 @@ module VX_alu_unit import VX_gpu_pkg::*; #(
.result_if (pe_result_if[PE_IDX_MDV])
);
`endif
+
+ `ifdef EXT_DOT8_ENABLE
+ VX_alu_dot8 #(
+ .INSTANCE_ID (`SFORMATF(("%s-dot8%0d", INSTANCE_ID, block_idx))),
+ .NUM_LANES (NUM_LANES)
+ ) dot8_unit (
+ .clk (clk),
+ .reset (reset),
+ .execute_if (pe_execute_if[PE_IDX_DOT8]),
+ .result_if (pe_result_if[PE_IDX_DOT8])
+ );
+ `endif
+
end
VX_gather_unit #(
diff --git a/hw/rtl/core/VX_decode.sv b/hw/rtl/core/VX_decode.sv
index 6669f263..647f22be 100644
--- a/hw/rtl/core/VX_decode.sv
+++ b/hw/rtl/core/VX_decode.sv
@@ -534,6 +534,29 @@ module VX_decode import VX_gpu_pkg::*; #(
endcase
end
`endif
+
+ `ifdef EXT_DOT8_ENABLE
+ 7'h09: begin
+ case (funct3)
+ 3'h0: begin // DOT8
+ ex_type = EX_ALU;
+ op_type = INST_OP_BITS'(INST_ALU_DOT8);
+ op_args.alu.xtype = ALU_TYPE_OTHER;
+ op_args.alu.is_w = 0;
+ op_args.alu.use_PC = 0;
+ op_args.alu.use_imm = 0;
+ use_rd = 1;
+ `USED_IREG (rd);
+ `USED_IREG (rs1);
+ `USED_IREG (rs2);
+
+ end
+ default:;
+ endcase
+ end
+ `endif
+
+
default:;
endcase
end
diff --git a/hw/rtl/core/VX_execute.sv b/hw/rtl/core/VX_execute.sv
index 3cce1d50..b8ad7e37 100644
--- a/hw/rtl/core/VX_execute.sv
+++ b/hw/rtl/core/VX_execute.sv
@@ -33,7 +33,7 @@ module VX_execute import VX_gpu_pkg::*; #(
VX_lsu_mem_if.master lsu_mem_if [`NUM_LSU_BLOCKS],
// dispatch interface
- VX_dispatch_if.slave dispatch_if [NUM_EX_UNITS * `ISSUE_WIDTH],
+ VX_dispatch_if.slave dispatch_if [NUM_EX_UNITS * `ISSUE_WIDTH], // 通过调整 ISSUE_WIDTH 来控制并发的规模, 在电路复杂度和性能上取得平衡
// commit interface
VX_commit_if.master commit_if [NUM_EX_UNITS * `ISSUE_WIDTH],
diff --git a/hw/rtl/libs/VX_find_first.sv b/hw/rtl/libs/VX_find_first.sv
index b497fd12..91176425 100644
--- a/hw/rtl/libs/VX_find_first.sv
+++ b/hw/rtl/libs/VX_find_first.sv
@@ -24,9 +24,10 @@ module VX_find_first #(
output wire [DATAW-1:0] data_out,
output wire valid_out
);
- localparam LOGN = `CLOG2(N);
- localparam TL = (1 << LOGN) - 1;
- localparam TN = (1 << (LOGN+1)) - 1;
+ localparam LOGN = `CLOG2(N); // 二叉树的层数
+ localparam TL = (1 << LOGN) - 1; // 叶子节点的起始索引, 0~TL 的索引存放排序后的结果
+ localparam TN = (1 << (LOGN+1)) - 1; // 总节点的个数
+
`IGNORE_UNOPTFLAT_BEGIN
wire s_n [TN];
@@ -34,21 +35,22 @@ module VX_find_first #(
`IGNORE_UNOPTFLAT_END
for (genvar i = 0; i < N; ++i) begin : g_fill
- assign s_n[TL+i] = REVERSE ? valid_in[N-1-i] : valid_in[i];
+ assign s_n[TL+i] = REVERSE ? valid_in[N-1-i] : valid_in[i]; // 根据 REVERSE 把数据按顺序放到叶子节点
assign d_n[TL+i] = REVERSE ? data_in[N-1-i] : data_in[i];
end
if (TL < (TN-N)) begin : g_padding
for (genvar i = TL+N; i < TN; ++i) begin : g_i
- assign s_n[i] = 0;
+ assign s_n[i] = 0; // 把多余的叶子节点用0 填充, => 未填充的叶子节点如果不赋值为0 则可能的值是X 或者被综合器用任意值填充, 导致算法结果不可预测
assign d_n[i] = '0;
end
end
for (genvar j = 0; j < LOGN; ++j) begin : g_scan
- localparam I = 1 << j;
+ // localparam I = 1 << j;
+ localparam I = 1 << j; // 表示当前层有 2^j 个节点
for (genvar i = 0; i < I; ++i) begin : g_i
- localparam K = I+i-1;
+ localparam K = I+i-1; // 计算当前节点在数组中的索引
assign s_n[K] = s_n[2*K+2] | s_n[2*K+1];
assign d_n[K] = s_n[2*K+1] ? d_n[2*K+1] : d_n[2*K+2];
end
diff --git a/hw/rtl/libs/VX_stream_switch.sv b/hw/rtl/libs/VX_stream_switch.sv
index fb263fd4..587b07db 100644
--- a/hw/rtl/libs/VX_stream_switch.sv
+++ b/hw/rtl/libs/VX_stream_switch.sv
@@ -75,11 +75,11 @@ module VX_stream_switch #(
end else if (NUM_OUTPUTS > NUM_INPUTS) begin : g_output_select
// Inputs < Outputs
-
+ // 为每个输入创建输出缓冲逻辑
for (genvar i = 0; i < NUM_INPUTS; ++i) begin : g_out_buf
logic [NUM_REQS-1:0] ready_out_s;
-
+ // 为每个请求创建对应的输出端口映射
for (genvar r = 0; r < NUM_REQS; ++r) begin : g_r
localparam o = r * NUM_INPUTS + i;
if (o < NUM_OUTPUTS) begin : g_valid
diff --git a/kernel/include/vx_intrinsics.h b/kernel/include/vx_intrinsics.h
index 71d4cd5b..da9cf0e2 100644
--- a/kernel/include/vx_intrinsics.h
+++ b/kernel/include/vx_intrinsics.h
@@ -281,6 +281,19 @@ inline __attribute__((const)) int vx_shfl_idx(size_t value, int bval, int cval,
return ret;
}
+// DOT8 funct7 设为9 避免以后项目添加新指令产生冲突
+// R type: .insn r opcode7, funct3, funct7, rd, rs1, rs2
+/* +--------+-----+-----+--------+----+---------+ */
+/* | funct7 | rs2 | rs1 | funct3 | rd | opcode7 | */
+/* +--------+-----+-----+--------+----+---------+ */
+/* 31 25 20 15 12 7 0 */
+
+inline int vx_dot8(int a, int b) {
+ size_t ret;
+ asm volatile (".insn r %1, 0, 9, %0, %2, %3" : "=r"(ret) : "i"(RISCV_CUSTOM0), "r"(a), "r"(b));
+ return ret;
+}
+
#ifdef __cplusplus
}
#endif
diff --git a/tests/regression/Makefile b/tests/regression/Makefile
index be3ccc96..8db25319 100644
--- a/tests/regression/Makefile
+++ b/tests/regression/Makefile
@@ -21,6 +21,7 @@ all:
$(MAKE) -C sgemm2
$(MAKE) -C madmax
$(MAKE) -C stencil3d
+ $(MAKE) -C dot8
run-simx:
$(MAKE) -C basic run-simx
@@ -42,6 +43,7 @@ run-simx:
$(MAKE) -C sgemm2 run-simx
$(MAKE) -C madmax run-simx
$(MAKE) -C stencil3d run-simx
+ $(MAKE) -C dot8 run-simx
run-rtlsim:
$(MAKE) -C basic run-rtlsim
@@ -63,6 +65,7 @@ run-rtlsim:
$(MAKE) -C sgemm2 run-rtlsim
$(MAKE) -C madmax run-rtlsim
$(MAKE) -C stencil3d run-rtlsim
+ $(MAKE) -C dot8 run-rtlsim
clean:
$(MAKE) -C basic clean
@@ -84,3 +87,4 @@ clean:
$(MAKE) -C sgemm2 clean
$(MAKE) -C madmax clean
$(MAKE) -C stencil3d clean
+ $(MAKE) -C dot8 clean
diff --git a/tests/regression/dot8/Makefile b/tests/regression/dot8/Makefile
new file mode 100644
index 00000000..f8e9ec9b
--- /dev/null
+++ b/tests/regression/dot8/Makefile
@@ -0,0 +1,14 @@
+ROOT_DIR := $(realpath ../../..)
+include $(ROOT_DIR)/config.mk
+
+PROJECT := dot8
+
+SRC_DIR := $(VORTEX_HOME)/tests/regression/$(PROJECT)
+
+SRCS := $(SRC_DIR)/main.cpp
+
+VX_SRCS := $(SRC_DIR)/kernel.cpp
+
+OPTS ?= -n32
+
+include ../common.mk
diff --git a/tests/regression/dot8/common.h b/tests/regression/dot8/common.h
new file mode 100644
index 00000000..db203b91
--- /dev/null
+++ b/tests/regression/dot8/common.h
@@ -0,0 +1,16 @@
+#ifndef _COMMON_H_
+#define _COMMON_H_
+
+#ifndef TYPE
+#define TYPE int8_t
+#endif
+
+typedef struct {
+ uint32_t grid_dim[2];
+ uint32_t size;
+ uint64_t A_addr;
+ uint64_t B_addr;
+ uint64_t C_addr;
+} kernel_arg_t;
+
+#endif
diff --git a/tests/regression/dot8/kernel.cpp b/tests/regression/dot8/kernel.cpp
new file mode 100644
index 00000000..1fce2dec
--- /dev/null
+++ b/tests/regression/dot8/kernel.cpp
@@ -0,0 +1,58 @@
+#include <cstdint>
+#include <vx_spawn.h>
+#include "common.h"
+#include <stdio.h>
+#include <vx_print.h>
+
+void MatrixMultiply(TYPE *A, TYPE *B, int32_t *C, int N) {
+ vx_printf("MatrixMultiply start (N=%d)\n", N);
+ // auto C = reinterpret_cast<uint32_t *>(C);
+ vx_printf("C point addr: 0x%x\n", C);
+
+ int32_t sum(0);
+ for (int i = 0; i < N; i+=4) {
+ // Pack A elements
+ uint32_t packedA = *((uint32_t *)&A[i]);
+ vx_printf(" packedA=0x%08x\n", packedA);
+
+ // Pack B elements
+ uint32_t packedB = (uint8_t)B[(i + 0) * N]
+ | ((uint8_t)B[(i + 1) * N] << 8)
+ | ((uint8_t)B[(i + 2) * N] << 16)
+ | ((uint8_t)B[(i + 3) * N] << 24);
+ vx_printf(" packedB=0x%08x (bytes: %x,%x,%x,%x)\n",
+ packedB,
+ (uint8_t)B[(i + 0) * N],
+ (uint8_t)B[(i + 1) * N],
+ (uint8_t)B[(i + 2) * N],
+ (uint8_t)B[(i + 3) * N]);
+
+ int32_t dot = vx_dot8(packedA, packedB);
+ // int32_t dot = packedA * packedB; // debug
+ vx_printf(" dot product=0x%08x (%d) C point: 0x%x\n", dot, dot, C);
+ sum += dot;
+ }
+ C[0] = sum;
+ vx_printf(" Final C = %d (0x%08x)\n", C[0], C[0]);
+
+ vx_printf("MatrixMultiply completed\n");
+}
+
+
+void kernel_body(kernel_arg_t* __UNIFORM__ arg) {
+ auto A = reinterpret_cast<TYPE*>(arg->A_addr);
+ auto B = reinterpret_cast<TYPE*>(arg->B_addr);
+ auto C = reinterpret_cast<int32_t*>(arg->C_addr);
+ auto size = arg->size;
+
+ int col = blockIdx.x;
+ int row = blockIdx.y;
+ vx_printf("row: %d, col: %d\n", row, col);
+ MatrixMultiply(&A[row*size], &B[col], &C[row * size + col], size);
+}
+
+
+int main() {
+ kernel_arg_t* arg = (kernel_arg_t*)csr_read(VX_CSR_MSCRATCH);
+ return vx_spawn_threads(2, arg->grid_dim, nullptr, (vx_kernel_func_cb)kernel_body, arg);
+}
diff --git a/tests/regression/dot8/main.cpp b/tests/regression/dot8/main.cpp
new file mode 100644
index 00000000..b4d9f135
--- /dev/null
+++ b/tests/regression/dot8/main.cpp
@@ -0,0 +1,301 @@
+#include <cstdint>
+#include <cstdio>
+#include <endian.h>
+#include <iostream>
+#include <unistd.h>
+#include <string.h>
+#include <vector>
+#include <chrono>
+#include <vortex.h>
+#include <cmath>
+#include "common.h"
+#include <iomanip>
+
+#define FLOAT_ULP 6
+
+#define RT_CHECK(_expr) \
+ do { \
+ int _ret = _expr; \
+ if (0 == _ret) \
+ break; \
+ printf("Error: '%s' returned %d!\n", #_expr, (int)_ret); \
+ cleanup(); \
+ exit(-1); \
+ } while (false)
+
+///////////////////////////////////////////////////////////////////////////////
+
+template <typename Type>
+class Comparator {};
+
+template <>
+class Comparator<int> {
+public:
+ static const char* type_str() {
+ return "integer";
+ }
+ static int generate() {
+ return rand();
+ }
+ static bool compare(int a, int b, int index, int errors) {
+ if (a != b) {
+ if (errors < 100) {
+ printf("*** error: [%d] expected=%d, actual=%d\n", index, b, a);
+ }
+ return false;
+ }
+ return true;
+ }
+};
+
+template <>
+class Comparator<float> {
+public:
+ static const char* type_str() {
+ return "float";
+ }
+ static int generate() {
+ return static_cast<float>(rand()) / RAND_MAX;
+ }
+ static bool compare(float a, float b, int index, int errors) {
+ union fi_t { float f; int32_t i; };
+ fi_t fa, fb;
+ fa.f = a;
+ fb.f = b;
+ auto d = std::abs(fa.i - fb.i);
+ if (d > FLOAT_ULP) {
+ if (errors < 100) {
+ printf("*** error: [%d] expected=%f, actual=%f\n", index, b, a);
+ }
+ return false;
+ }
+ return true;
+ }
+};
+
+template <>
+class Comparator<int8_t> {
+public:
+ static const char* type_str() {
+ return "int8_t";
+ }
+ static int8_t generate() {
+ return static_cast<int8_t>(rand() % 256); // Generate value between 0-255
+ }
+ static bool compare(int a, int b, int index, int errors) {
+ if (a != b) {
+ if (errors < 100) {
+ printf("*** error: [%d] expected=0x%x, actual=0x%x\n", index, b, a);
+ }
+ return false;
+ }
+ return true;
+ }
+};
+
+static void matmul_cpu(int32_t *out, const TYPE *A, const TYPE *B, uint32_t size) {
+ printf("matmul_cpu Starting matrix multiplication (size: %u)\n", size);
+ for (uint32_t row = 0; row < size; ++row) {
+ printf("Processing row %u\n", row);
+ for (uint32_t col = 0; col < size; ++col) {
+ int32_t sum(0);
+ printf(" Calculating element [%u][%u]\n", row, col);
+ for (uint32_t i = 0; i < size; i++) {
+ TYPE a = A[row * size + i];
+ TYPE b = B[i * size + col];
+ printf(" A[%u][%u]=%d (0x%x), B[%u][%u]=%d (0x%x)\n", row, i, a, a, i, col, b, b);
+ sum += a * b;
+ }
+ out[row * size + col] = sum;
+ printf(" Result[%u][%u] =%d (0x%x)\n", row, col, sum, sum);
+ }
+ }
+ printf("Matrix multiplication completed\n");
+}
+
+
+const char* kernel_file = "kernel.vxbin";
+uint32_t size = 32;
+
+vx_device_h device = nullptr;
+vx_buffer_h A_buffer = nullptr;
+vx_buffer_h B_buffer = nullptr;
+vx_buffer_h C_buffer = nullptr;
+vx_buffer_h krnl_buffer = nullptr;
+vx_buffer_h args_buffer = nullptr;
+kernel_arg_t kernel_arg = {};
+
+static void show_usage() {
+ std::cout << "Vortex Test." << std::endl;
+ std::cout << "Usage: [-k: kernel] [-n size] [-h: help]" << std::endl;
+}
+
+static void parse_args(int argc, char **argv) {
+ int c;
+ while ((c = getopt(argc, argv, "n:k:h")) != -1) {
+ switch (c) {
+ case 'n':
+ size = atoi(optarg);
+ break;
+ case 'k':
+ kernel_file = optarg;
+ break;
+ case 'h':
+ show_usage();
+ exit(0);
+ break;
+ default:
+ show_usage();
+ exit(-1);
+ }
+ }
+}
+
+void cleanup() {
+ if (device) {
+ vx_mem_free(A_buffer);
+ vx_mem_free(B_buffer);
+ vx_mem_free(C_buffer);
+ vx_mem_free(krnl_buffer);
+ vx_mem_free(args_buffer);
+ vx_dev_close(device);
+ }
+}
+
+int main(int argc, char *argv[]) {
+ // parse command arguments
+ parse_args(argc, argv);
+
+ std::srand(50);
+
+ // open device connection
+ std::cout << "open device connection" << std::endl;
+ RT_CHECK(vx_dev_open(&device));
+
+ uint32_t size_sq = size * size;
+ uint32_t buf_size = size_sq * sizeof(TYPE);
+ uint32_t C_buf_size = buf_size * 4;
+
+ std::cout << "data type: " << Comparator<TYPE>::type_str() << std::endl;
+ std::cout << "matrix size: " << size << "x" << size << std::endl;
+
+ kernel_arg.grid_dim[0] = size;
+ kernel_arg.grid_dim[1] = size;
+ kernel_arg.size = size;
+
+ // allocate device memory
+ std::cout << "allocate device memory" << std::endl;
+ RT_CHECK(vx_mem_alloc(device, buf_size, VX_MEM_READ, &A_buffer));
+ RT_CHECK(vx_mem_address(A_buffer, &kernel_arg.A_addr));
+ RT_CHECK(vx_mem_alloc(device, buf_size, VX_MEM_READ, &B_buffer));
+ RT_CHECK(vx_mem_address(B_buffer, &kernel_arg.B_addr));
+ RT_CHECK(vx_mem_alloc(device, C_buf_size, VX_MEM_WRITE, &C_buffer));
+ RT_CHECK(vx_mem_address(C_buffer, &kernel_arg.C_addr));
+
+ std::cout << "A_addr=0x" << std::hex << kernel_arg.A_addr << std::endl;
+ std::cout << "B_addr=0x" << std::hex << kernel_arg.B_addr << std::endl;
+ std::cout << "C_addr=0x" << std::hex << kernel_arg.C_addr << std::endl;
+
+ // generate source data
+ std::vector<TYPE> h_A(size_sq);
+ std::vector<TYPE> h_B(size_sq);
+ std::vector<int32_t> h_C(size_sq);
+ for (uint32_t i = 0; i < size_sq; ++i) {
+ h_A[i] = Comparator<TYPE>::generate();
+ h_B[i] = Comparator<TYPE>::generate();
+ }
+
+ // 打印矩阵 h_A
+ std::cout << "Matrix A (" << size << "x" << size << "):\n";
+ for (uint32_t row = 0; row < size; ++row) {
+ for (uint32_t col = 0; col < size; ++col) {
+ std::cout << "0x"
+ << std::hex << std::setw(2) << std::setfill('0')
+ << static_cast<int>(static_cast<uint8_t>(h_A[row * size + col])) << " ";
+ }
+ std::cout << "\n";
+ }
+
+ // 打印矩阵 h_B
+ std::cout << "\nMatrix B (" << size << "x" << size << "):\n";
+ for (uint32_t row = 0; row < size; ++row) {
+ for (uint32_t col = 0; col < size; ++col) {
+ std::cout << "0x"
+ << std::hex << std::setw(2) << std::setfill('0')
+ << static_cast<int>(static_cast<uint8_t>(h_B[row * size + col])) << " ";
+ }
+ std::cout << "\n";
+ }
+ std::cout << std::dec << std::endl; // 恢复十进制输出
+
+
+
+ // upload matrix A buffer
+ {
+ std::cout << "upload matrix A buffer" << std::endl;
+ RT_CHECK(vx_copy_to_dev(A_buffer, h_A.data(), 0, buf_size));
+ }
+
+ // upload matrix B buffer
+ {
+ std::cout << "upload matrix B buffer" << std::endl;
+ RT_CHECK(vx_copy_to_dev(B_buffer, h_B.data(), 0, buf_size));
+ }
+
+ // upload program
+ std::cout << "upload program" << std::endl;
+ RT_CHECK(vx_upload_kernel_file(device, kernel_file, &krnl_buffer));
+
+ // upload kernel argument
+ std::cout << "upload kernel argument" << std::endl;
+ RT_CHECK(vx_upload_bytes(device, &kernel_arg, sizeof(kernel_arg_t), &args_buffer));
+
+ auto time_start = std::chrono::high_resolution_clock::now();
+
+ // start device
+ std::cout << "start device" << std::endl;
+ RT_CHECK(vx_start(device, krnl_buffer, args_buffer));
+
+ // wait for completion
+ std::cout << "wait for completion" << std::endl;
+ RT_CHECK(vx_ready_wait(device, VX_MAX_TIMEOUT));
+
+ auto time_end = std::chrono::high_resolution_clock::now();
+ double elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(time_end - time_start).count();
+ printf("Elapsed time: %lg ms\n", elapsed);
+
+ // download destination buffer
+ std::cout << "download destination buffer" << std::endl;
+ RT_CHECK(vx_copy_from_dev(h_C.data(), C_buffer, 0, C_buf_size));
+
+ // verify result
+ std::cout << "verify result" << std::endl;
+ int errors = 0;
+ {
+ std::vector<int32_t> h_ref(size_sq);
+ matmul_cpu(h_ref.data(), h_A.data(), h_B.data(), size);
+ uint32_t int_size = (int32_t)(h_ref.size() / 4);
+
+ auto int_h_C = reinterpret_cast<int32_t *>(h_C.data());
+ auto int_h_ref = reinterpret_cast<int32_t *>(h_ref.data());
+
+ for (uint32_t i = 0; i < int_size; ++i) {
+ if (!Comparator<TYPE>::compare(int_h_C[i], int_h_ref[i], i, errors)) {
+ ++errors;
+ }
+ }
+ }
+
+ // cleanup
+ std::cout << "cleanup" << std::endl;
+ cleanup();
+
+ if (errors != 0) {
+ std::cout << "Found " << std::dec << errors << " errors!" << std::endl;
+ std::cout << "FAILED!" << std::endl;
+ return errors;
+ }
+
+ std::cout << "PASSED!" << std::endl;
+ return 0;
+}
|